Как выглядят задержки индексации при массовой публикации
Задержки индексации обычно следуют одному сценарию: вы публикуете, страница доступна, но не появляется в поиске днями (иногда неделями). При небольшом объёме это легко не заметить. Когда вы выпускаете десятки URL в день, задержка становится очевидной — новые страницы накапливаются быстрее, чем попадают в индекс.
Обычный признак — статус в Search Console вроде «Сканировано, в настоящее время не индексируется». Это значит, что бот посетил URL, но не сохранил его как результат поиска. Другой сценарий: индексируется только часть самых новых страниц, в то время как старые разделы сайта продолжают работать нормально.
Когда вы переходите с 10 страниц до 1 000+, краулерам приходится выбирать, куда тратить время. Если сайт генерирует много похожих URL (дубликаты, тонкие страницы, варианты с параметрами), боты могут тратить визиты не на те страницы. Те страницы, которые вам действительно важны, остаются в очереди.
Частые причины массовых проблем «сканировано, но не индексируется»:
- Страница слишком похожа на существующие (повторяемые шаблоны, одинаковые вводные, близкие темы).
- Страница кажется неважной (мало внутренних ссылок, глубоко в пагинации).
- Страница отправляет смешанные технические сигналы (неверный canonical, случайный
noindex, заблокированные ресурсы).
- Сайт генерирует слишком много малоценностных URL (фильтры, трекинговые параметры, фасетная навигация).
- Контент не удовлетворяет запрос (тонкий, устаревший или отсутствуют ключевые детали).
Быстрый способ отделить проблемы качества от проблем обнаружения — взять небольшую выборку новых URL (например, 20) и задать два вопроса.
Первый: может ли краулер легко обнаружить страницу? Проверьте, что URL есть в XML sitemap, имеет хотя бы одну заметную внутреннюю ссылку, возвращает 200 OK и не заблокирован правилами robots.
Второй: если обнаружен, стоит ли его индексировать? Оцените реальную уникальность (не перефразирование существующей страницы), соответствие намерению (отвечает на реальный вопрос) и достаточность содержания (конкретика и примеры, а не только шаблон).
Если большинство в выборке не проходят первый тест — это проблема системы обнаружения. Если проходят обнаружение, но проваливают второй — проблема качества и дублирования. Исправьте нужную сторону, и очередь обычно быстро сократится.
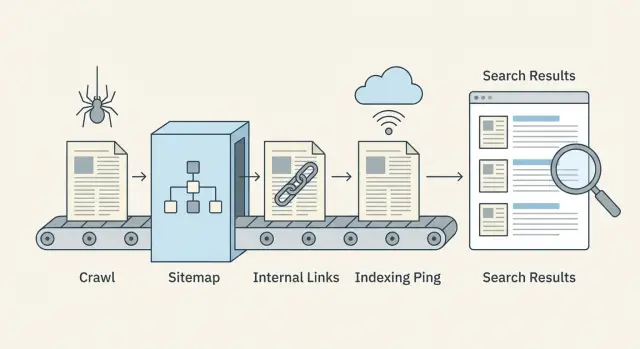
Процесс от краулинга до индексации простыми словами
Публикация не делает страницу мгновенно доступной в поиске. Поисковые системы пропускают её через конвейер, и задержки могут возникать на любом этапе.
Обнаружение, краулинг и индексация (что это значит)
Обнаружение — когда поисковая система узнаёт, что URL существует. Это происходит через внутренние ссылки, XML sitemap или внешние упоминания.
Краулинг — когда бот заходит на URL и загружает видимое содержимое (HTML, важные ресурсы и иногда дополнительные связанные URL). Краулинг ограничен временем и вниманием, поэтому некоторые страницы посещаются поздно или редко.
Индексация — когда поисковая система решает, хранить ли страницу и показывать ли её в результатах, и по каким запросам. Сканирование страницы не гарантирует её индексацию.
Поток выглядит так:
- Поисковая система находит URL (обнаружение)
- Бот скачивает страницу (краул)
- Страница оценивается и либо сохраняется, либо пропускается (индекс)
- Позиции обновляются со временем по мере накопления сигналов
Где обычно происходят задержки
Большинство замедлений происходит до того, как бот добирается до страницы, или сразу после её сканирования.
Задержки обнаружения проявляются, когда новые страницы осиротели (на них нет ссылок) или когда sitemap устарел.
Задержки краулинга часто вызваны тратой краулов на малоценностные URL (дубли, фасеты, параметрический спам) или медленным ответом сервера.
Задержки индексации возникают, когда страницы выглядят слишком похожими на другие, имеют тонкий контент, отправляют смешанные сигналы (canonical на другой URL, случайный noindex) или загружают ключевой контент с задержкой.
Сигналы, которые можно поменять быстро и медленно
Быстрые рычаги — в основном технические и структурные: более сильные внутренние ссылки с уже просканированных страниц, точные sitemap, меньше ловушек для краулеров, лучшие времена ответа и проактивные пинги индексации, когда это уместно.
Медленные рычаги требуют времени: общее качество сайта, последовательность, естественные ссылки и долгосрочные сигналы вовлечённости.
Что измерять еженедельно
Не нужен сложный дашборд, чтобы заметить проблемы. Отслеживайте несколько показателей каждую неделю:
- Новые URL, опубликованные vs. новые URL, попавшие в индекс
- Медианное время от публикации до первого краула
- Ошибки краулинга и медленные ответы (5xx, тайм-ауты)
- Доля «Discovered, currently not indexed» и «Crawled, currently not indexed»
- Покрытие sitemap: URL в sitemap vs. реально индексируемые URL
Crawl budget: перестаньте тратить краулы на малоценные страницы
Публиковать в большом объёме — это не только про создание хороших страниц. Это ещё и про то, чтобы краулерам было легко тратить время на действительно важные страницы.
Бюджет краулинга расходуется, когда боты постоянно натыкаются на множество версий одного и того же контента или на страницы с малой ценностью. Типичные виновники: параметры URL (сортировка, трекинг), фасетные фильтры, архивы по тегам, печатные версии и страницы, которые едва чем-то отличаются друг от друга.
Признаки утечки crawl budget:
- Много URL, отличающихся только параметрами вроде
?sort= или ?ref=.
- Фильтры, порождающие бесконечные комбинации (color=, size=, brand=).
- Тонкие страницы, повторяющиеся по разным URL.
- Цепочки редиректов (несколько перескоков до финальной страницы).
- Резкие всплески 404/500 ошибок или тайм-аутов в логах сервера.
Скорость и ошибки напрямую влияют на частоту возврата ботов. Если сайт медленный или часто выдаёт ошибки, краулеры уменьшают посещения, чтобы не тратить ресурсы. Исправление 5xx ошибок, сокращение тайм-аутов и улучшение времени ответа может увеличить частоту краулинга больше, чем простая публикация ещё большего объёма страниц.
Блокировка малоценных разделов помогает, но делайте это аккуратно. Блокируйте действительно бесполезные области (бесконечные комбинации фильтров, внутренний поиск, страницы календаря, генерирующие тысячи URL). Не блокируйте страницы, которые вы хотите видеть в индексе, только потому что они новые. Если страница должна ранжироваться позже, ей всё равно нужно быть доступной для краулеров сейчас.
Снижайте дублирование без изменения CMS
Даже если вы не можете легко изменить генерацию URL, вы можете уменьшить дублирующие сигналы:
- Добавьте canonical-теги, чтобы параметризованные версии указывали на основной URL.
- Используйте последовательные внутренние ссылки, которые всегда ведут на чистый URL.
- Удалите параметризованные URL из XML sitemap.
- Добавьте правила в robots.txt для очевидного мусора (только если вы уверены).
- Нормализуйте редиректы, чтобы старые варианты решались одним прыжком.
Пример: страница категории в e‑commerce может существовать как /shoes, плюс /shoes?sort=price и /shoes?color=black. Держите /shoes индексируемой и ссылайтесь на неё внутри. Канонизируйте вариации обратно на /shoes и уберите вариации из sitemap. Это направит краулеров к нужной странице и убережёт от циклов.
Внутренние ссылки, которые помогают новым страницам быть обнаруженными
При большом объёме публикаций внутренние ссылки — ваш самый быстрый сигнал обнаружения. Поисковые системы могут сканировать только то, что они могут найти. Если новые URL не связаны со страницами, которые уже краулеры посещают, они часто остаются незамеченными, даже если sitemap идеален.
Стройте кластеры, которые естественно поднимают новые страницы
Думайте в категориях тем: одна сильная основная страница (гайд, страница категории, термин глоссария или FAQ) и поддерживающие статьи, отвечающие на конкретные вопросы. Когда вы добавляете новую поддерживающую статью, свяжите её с основной страницей и с 1–2 смежными материалами. Затем сделайте обратную ссылку на основную страницу.
Пример: основная страница «Основы email‑маркетинга» может ссылаться на новые материалы «Примеры welcome‑письем» и «Как очистить список». Новые страницы ссылаются обратно на ядро, и краулеры продолжают перемещаться по кластеру вместо того, чтобы останавливаться.
Используйте простой хаб для нового контента
Страница «Новый контент» помогает, когда вы публикуете ежедневно или ежечасно. Она не должна быть сложной — достаточно, чтобы её было легко найти из навигации или с главной и чтобы она обновлялась автоматически.
Держите её аккуратной: показывайте недавние посты по темам и избегайте бесконечной прокрутки. Такой хаб станет надёжным местом, куда краулеры будут часто возвращаться.
Анкор‑тексты важны, но в здравом смысле. Используйте понятные слова, описывающие страницу ("чеклист welcome‑письма"), а не расплывчатые ярлыки ("кликните сюда") и не переспам ключевыми словами.
Правила для первой недели после публикации работают так:
- Ссылайтесь на каждую новую страницу как минимум с 2 уже крауленных страниц (хаб или категория считается за одну).
- Добавьте 1 контекстную ссылку из близкой по теме старой статьи.
- Ссылайтесь обратно на основную страницу темы, чтобы кластер оставался связанным.
- Держите число ссылок разумным, чтобы важные ссылки выделялись.
Следите за осиротевшими страницами (без внутренних входящих ссылок). Практический способ обнаружить их — сравнить список опубликованных URL (или sitemap) с результатами полного обхода сайта и посмотреть, какие URL не помечены как «внутренние ссылки». Любой URL без внутренних ссылок — риск обнаружения.
Если ваша система публикации поддерживает это, встраивайте внутренние ссылки в шаг публикации, чтобы новые страницы не оставались без ссылок в первый день.
Sitemaps, которые остаются актуальными при большом объёме
При большом объёме XML sitemap перестаёт быть «приятным дополнением» и становится панелью управления. Она показывает поисковым системам, что изменилось и что важно.
Что включать (и что исключать)
В sitemap должны попадать только URL, которые вы действительно хотите индексировать и которые краулер может успешно загрузить.
Включайте страницы, которые:
- Индексируемы (не заблокированы robots, не помечены
noindex)
- Каноничны сами себе (или вы уверены, что указанный URL — канонический)
- Возвращают
200 и рендерят реальный контент
Исключайте фасетные фильтры, внутренний поиск, бесконечные параметрические URL, дубликаты и тонкие страницы, которые вы не хотите ранжировать. Если URL — тупик для пользователей, он обычно и для краулинга будет тупиком.
Как часто обновлять при частых публикациях
Если вы публикуете ежедневно или чаще, рассматривайте sitemap как поток в реальном времени. Обновляйте его при выходе новых страниц и удаляйте URL, которые уже не существуют или больше не индексируемы. Ожидание неделю может привести к тому, что краулеры будут сканировать старые страницы и пропустят ваши новые.
Используйте поле lastmod только когда вы можете устанавливать его честно. Оно должно отражать содержательные изменения, а не любую мелкую правку или повторное сохранение. Завышенные даты lastmod приучают краулеров не доверять этому полю.
Работа с большими сайтами: несколько sitemap и индекс sitemap
По мере роста сайта разделяйте sitemap по типу (посты в блоге, глоссарий, новости) или по времени (по месяцам). Меньшие sitemap обновляются быстрее, и с ними проще работать.
Индекс sitemap служит каталогом, указывающим на каждый файл sitemap. Он также помогает распределить ответственность в команде: один человек может отвечать за sitemap блога, другой — за продуктовые или глоссарные URL.
Проверки гигиены sitemap, которые ловят проблемы рано
Проводите эти проверки регулярно, особенно после крупных релизов:
- URL возвращают
200 (не 3xx, 4xx или 5xx)
- Указанные URL совпадают с каноническим URL страницы
- Страницы с
noindex не включены
lastmod меняется только при реальных изменениях контента- Sitemap не растёт за счёт дубликатов или параметризованных URL
Если вы генерируете страницы через API или CMS, автоматизируйте эти проверки, чтобы ошибки не масштабировались вместе с объёмом.
Canonical, noindex и проверки robots перед публикацией
При большом объёме маленькие технические ошибки быстро накапливаются. Одна неверная настройка в шаблоне может скрыть сотни страниц из поиска или захламить краулеров дубликатами.
Выберите один предпочитаемый формат URL
Поисковым системам нужен один главный вариант каждой страницы. Решите предпочитаемый формат и придерживайтесь его: HTTPS vs HTTP, www vs non‑www, слэш в конце vs без слэша.
Если сайт доступен по нескольким вариантам (например, со слэшем и без), вы создаёте копии, которые выглядят одинаково. Это замедляет обнаружение и делает индексацию менее предсказуемой.
Канонические и индексные настройки: что проверить
Канонические теги говорят поисковым системам: «Эта страница — копия, индексируйте другой URL». Они помогают с близкими дубликатами (печать, фильтры, похожие страницы по локациям), но опасны при широком применении.
Обычная ошибка: новый шаблон блога случайно ставит канонический URL на главную блога для каждого поста. Боты всё ещё скачивают страницы, но индексация тормозится, потому что каждая страница «заявляет», что основной URL — другой.
Перед публикацией батча выборочно проверьте несколько новых URL:
- Канонический тег указывает на саму страницу для обычных страниц (не на категорию или главную).
- Страница индексируема (нет meta
noindex и нет X-Robots-Tag: noindex).
- robots.txt позволяет краулинг путей, которые используют новые страницы.
- Редиректы приходят в один шаг (избегайте цепочек).
- Финальный URL соответствует предпочитаемому варианту (тот же хост, протокол и стиль со слэшем).
Также обратите внимание на «шумовые» страницы. Теги, категории и пагинация полезны для пользователей, но могут порождать бесконечные малоценностные URL, если система генерирует много комбинаций. Этот шум конкурирует с новым контентом за внимание краулеров.
Практическое правило: держите важные хаб‑страницы доступными для краулеров, но предотвращайте размножение тонких или повторяющихся вариантов.
Пошаговый масштабируемый рабочий процесс публикации и индексации
Относитесь к каждому батчу как к небольшому релизу. Цель — выпускать страницы, которые легко сканировать, легко понять и которые сразу связаны с остальным сайтом.
1) Подготовка батча (перед публикацией)
Быстрые проверки шаблонов и контента, чтобы не создать 200 новых проблем одновременно:
- Убедитесь, что каждая страница возвращает
200 OK (нет случайных 404, редиректов или блокировки рендеринга).
- Проверьте, что есть title, meta description и один понятный заголовок уровня H1, и они не дублируются по батчу.
- Убедитесь, что canonical‑теги указывают на правильный предпочитаемый URL.
- Добавляйте структурированные данные только если они точны (например, Article для постов блога).
- Убедитесь, что страницы индексируемы (noindex выключен, правила robots позволяют краулинг).
Если можно — растяните релизы. Публиковать 50 страниц в день в течение 4 дней легче отслеживать, чем выложить 200 за час, и это помогает раньше обнаружить ошибки шаблонов.
2) Публикация и оперативное обеспечение обнаружения (в течение минут)
Публикация — это не финиш. Новым URL нужны понятные пути с уже известной территории.
После выката батча сосредоточьтесь на трёх действиях: добавьте внутренние ссылки с релевантных хаб‑страниц, обновите XML sitemap и отправьте обоснованный пинг индексации (например, IndexNow) только для новых URL.
3) Мониторинг первых 48 часов (и что делать, если ничего не появилось)
Дайте поисковым системам время, но не ждите слепо. В первые день‑два выберите 10 URL и проверьте, доступны ли они, связаны ли внутренними ссылками и включены ли в sitemap.
Если через 48 часов они всё ещё не показываются, приоритетно устраните проблемы обнаружения:
- Добавьте более сильные внутренние ссылки (с популярных страниц, страниц категорий и недавних постов).
- Удалите ловушки краулинга (бесконечные фильтры, страницы тегов‑дубликатов, внутренний поиск).
- Повторно проверьте canonical и noindex (одна неверная настройка может скрыть весь шаблон).
- Убедитесь, что sitemap содержит новые URL и что
lastmod ведёт себя корректно.
- Повторно отправьте пинг индексации только для URL, которые вы поменяли или только что добавили.
Пример: если вы публикуете 120 страниц глоссария, также опубликуйте (или обновите) 3–5 хаб‑страниц, которые ссылаются на них. Хабы часто краулатся первыми и тянут за собой новые страницы.
Проактивные пинги индексации (включая IndexNow) — ответственно
Пинги индексации — полезный толчок, но не волшебная кнопка. Они работают лучше всего при большом объёме публикаций, когда вы хотите, чтобы поисковые системы заметили изменения быстрее, особенно для срочных обновлений (изменения цен, статус в наличии, срочные новости) или при удалении URL, когда нужно, чтобы они ушли из индекса быстрее.
Они бесполезны, если страница заблокирована robots.txt, помечена noindex, лишена внутренних ссылок или возвращает ошибки. В таких случаях пинги лишь быстрее приведут краулеров к тупику.
Что делает IndexNow (простыми словами)
IndexNow — это простой сигнал «этот URL изменился», который вы отправляете участвующим поисковым системам. Вместо того, чтобы ждать, пока краулеры снова обнаружат изменения, вы даёте список новых, обновлённых или удалённых URL. Поисковые системы могут затем решить просканировать эти URL раньше. Индексация остаётся их решением, но обнаружение часто ускоряется.
Пример: вы обновили 200 старых постов новыми разделами. Без пингов краулеры могут тратить дни или недели на повторное посещение всех них. С IndexNow вы указываете точные URL, которые изменились.
Привязывайте пакеты пингов к реальным изменениям:
- Новые URL, которые возвращают
200 и имеют внутренние ссылки
- Обновлённые URL с содержательными изменениями
- Удалённые URL (
404/410) или перенаправленные URL (301) после внесённых изменений
- Только канонические URL (избегайте вариаций с параметрами и трекинговых URL)
Шум — самый быстрый путь обесценить пинги. Не пингуйте один и тот же URL каждый час, не отправляйте URL до их доступности и не шлите огромные списки, когда изменилось лишь несколько страниц.
Типичные ошибки, вызывающие задержки индексации при масштабе
Задержки индексации редко являются проблемой поисковой системы. Чаще это ошибки, которые мы сами создаём. Цель проста: облегчить краулерам жизнь для ваших лучших URL и усложнить им тратить время на всё остальное.
Одна распространённая ловушка — массовая генерация страниц, которые выглядят по‑разному для вас, но не для краулера. Если сотни страниц отличаются только названием города, прилагательным продукта или несколькими фразами, их могут воспринять как близкие дубликаты. Краулеры замедлятся, индексируют меньше страниц или выберут другую версию вместо нужной вам.
Другой убийца crawl budget — неконтролируемый рост URL. Фасеты, внутренний поиск, страницы тегов, архивы и трекинговые параметры могут размножиться до тысяч сканируемых URL. Даже если они безвредны, они конкурируют с новым контентом за внимание.
Частые ошибки:
- Публикация больших партий очень похожих страниц без уникальной ценности.
- Позволять тегам, фильтрам, внутреннему поиску и параметрам генерировать бесконечные варианты URL.
- Полагаться только на sitemap без сильных внутренних ссылок с релевантных хабов.
- Включать в sitemap перенаправляющиеся, неканонические, заблокированные или
noindex URL.
- Переименовывать или перемещать URL сразу после запуска, вызывая повторные сканирования, редиректы и дублирующие сигналы.
Пример: блог о недвижимости публикует 500 гайдов по районам за неделю. Если каждый гид — в основном шаблон с заменёнными фразами, и сайт одновременно открывает бесконечные комбинации фильтров (кол‑во комнат, цена, сортировка), краулеры могут застрять на фильтрах, а гиды останутся незамеченными.
Исправление обычно не в «делать больше», а в «уплотнить сигналы»: связывайте новые страницы с несколькими посещаемыми страницами категории, держите sitemap чистым и не меняйте URL, пока страницы не успеют прокраулиться и устояться.
Быстрый чеклист и следующие шаги
Маленькие проблемы быстро накапливаются при большом объёме. Эти проверки помогут не дать новым URL застрять.
Быстрый чеклист перед публикацией (для каждой страницы)
- Reachable and fast: возвращает
200, без цепочек редиректов и серверных ошибок.
- Indexable: нет случайного
noindex, нет блокировки robots, не за авторизацией.
- Canonical is clean: указывает на правильный финальный URL (не staging, не параметризованный URL).
- Discoverable: как минимум одна релевантная внутренняя ссылка с индексируемой страницы.
- Included in your sitemap: находится в правильном XML sitemap с корректным
lastmod и без дубликатов.
Если любой пункт провален — исправьте до дальнейшей публикации. Иначе вы создадите очередь, где краулеры будут возвращаться к неправильным URL.
Простая еженедельная рутина (15–30 минут)
Выделяйте один день в неделю на лёгкую уборку:
- Выбирайте несколько новых URL и проверяйте, что они краулятся и индексируются.
- Удаляйте из sitemap перенаправляющиеся, канонизированные,
noindex и битые URL.
- Следите за всплесками 5xx ошибок, медленным временем ответа и ростом редиректов.
- Обрезайте тонкие страницы тегов, дубликаты и параметризованные страницы, которые не должны краулиться.
Если команда копирует URL в таблицы, вручную правит sitemap и шлёт запросы на индексацию вручную, автоматизация обычно становится переломным моментом. Некоторые команды используют систему вроде GENERATED (generated.app) для генерации и доработки контента, поддержания актуальности sitemap и отправки IndexNow пингов как части API‑ориентированного рабочего процесса публикации, чтобы процесс оставался стабильным по мере роста объёма.