29 нояб. 2025 г.·7 мин. чтения
Конвейер контента с API: пошаговая архитектура
Постройте конвейер контента с API — от идеи до публикации: генерация, проверка, утверждение, планирование и мониторинг с простой архитектурой, которую можно адаптировать.
Какая проблема решается конвейером контента
Конвейер контента — это набор шагов, который превращает идею «надо это опубликовать» в живую страницу. Обычно в него входят черновик, редактирование, метаданные, изображения, утверждения и публикация. Когда конвейер понятен, все знают, что будет дальше, и работа не теряется в чатах.
Большинство команд теряют время не на написание как таковое, а на мелкие повторяющиеся задачи вокруг него: копирование текста между инструментами, ожидание обратной связи, исправление форматирования, проверка длины заголовка, добавление alt‑текста, загрузка изображений в нужных размерах и планирование постов. Те же ошибки повторяются, потому что процесс живет в головах людей.
Пайплайн на базе API превращает эти повторяющиеся задачи в предсказуемые запросы между системами: вашей CMS, бэкендом и сервисами, которые генерируют или валидируют контент. Это не значит, что публикация происходит без контроля. Это значит, что скучные части выполняются по умолчанию (создание черновика, форматирование, предложения по метаданным, варианты изображений, обновления статуса), а людям остается контролировать, что будет опубликовано.
Практичное определение «автоматического» выглядит так:
- Черновики могут генерироваться и подготавливаться автоматически, но публикация происходит только из утверждённого статуса.
- Правила применяются по умолчанию (обязательные поля, базовые SEO), но редакторы могут переопределить их при необходимости.
- Изменения логируются автоматически, но финальная подпись остаётся за человеком.
Такой подход окупается, когда вы часто публикуете, повторно используете контент в разных местах или хотите единообразие между авторами. Если вы публикуете редко и процесс уже простой, ручная публикация может быть быстрее.
Пример: небольшая маркетинговая команда пишет апдейты продукта в headless CMS. Один человек делает черновик, другой редактирует, третий занимается изображениями и планированием. С API‑воркфлоу новый черновик можно создать из шаблона, заполнить предложенными метаданными и автоматически получить варианты изображений нужных размеров. Редактор тогда сосредоточится на точности, ясности и голосе.
Базовые этапы и роли
API‑управляемый конвейер лучше всего работает, когда у всех одни и те же стадии. Нужно достаточно структуры, чтобы избежать хаоса, но не так много, чтобы публикация превратилась в серию совещаний.
У большинства команд получается пять этапов:
- Brief (что писать и зачем)
- Draft (первый вариант)
- Review (проверка качества, соответствия бренду и фактов)
- Publish (планирование и выход в эфир)
- Measure (анализ того, что сработало, а что нет)
Каждый этап должен иметь явного ответственного и выдавать конкретные данные для следующего шага.
Кто за что отвечает
Роли могут быть штатными позициями или просто «шляпами», которые люди носят. Важно, чтобы на каждом шаге был один назначенный ответственный.
Простое разделение ролей:
- Requester: определяет тему, аудиторию, цель и ограничения (тона, длина, ключевые пункты).
- Editor: улучшает ясность и структуру, проверяет базовое SEO, отмечает недостающую информацию.
- Approver: подписывает окончательно по точности, юридическим и бренд‑утверждениям.
- Publisher: планирует, добавляет метаданные и отправляет на сайт.
CMS vs сервис бэкенда
В этой схеме CMS — это место, где живёт контент и где работают люди: черновики, комментарии, утверждения и поля публикации. Бэкенд‑сервис — это слой автоматизации: он вызывает API генерации, применяет правила, хранит логи и переводит элементы по статусам.
Полезная мысленная модель: CMS — источник правды для статьи, а бэкенд — регулировщик трафика.
Через стадии надо надёжно передавать несколько вещей: бриф, текст статьи, SEO‑поля (заголовок, описание, ключевые слова), ассеты (промпты для изображений и финальные ID изображений), владение (кому назначено) и временные метки статусов для отслеживания.
Пример: requester создаёт короткий бриф в CMS. Бэкенд подхватывает его, генерирует черновик и предлагаемые метаданные и возвращает всё в CMS для редактирования. После утверждения публикация планируется. Позже бэкенд записывает показатели эффективности, чтобы следующий бриф был более конкретным.
Определите модель контента и статусы
Автоматизация работает лучше, когда каждый объект контента — предсказуемый объект, а не размытый документ. Прежде чем автоматизировать генерацию, обзор и публикацию, решите, какие поля вы храните и что значит «готово» на каждом шаге.
Начните с одного объекта контента, который может перемещаться по системе. Держите его простым, но достаточно полным, чтобы редактор мог проверить его без поисков недостающей информации.
Практичный набор полей:
- Title и slug (или URL key)
- Outline (заголовки и ключевые пункты)
- Body (полный текст статьи)
- Images (промпты, alt‑текст, финальные ID изображений)
- Metadata (description, теги, целевое ключевое слово, canonical, автор)
Статусы — вторая половина модели. Они должны быть понятными, взаимоисключающими и привязанными к правам доступа. Распространённый набор:
- Draft
- In review
- Approved
- Scheduled
- Published
Трактуйте статус как контракт между людьми и автоматизацией. Инструменты генерации могут писать в Draft, но только редактор (или заданное правило утверждения) должен переводить в Approved. Планирование должно хранить publish_at и позволять изменения до выхода в эфир.
История ревизий делает автоматизацию безопасной. Храните revision ID для каждого значимого изменения, вместе с тем, кто его сделал и почему. Полезная запись включает: предыдущее значение, новое значение, ID редактора, временную метку и опциональную заметку вроде «исправлена фактическая неточность» или «обновлено описание мета». Если вы используете инструмент генерации, например GENERATED, сохраните также ID запроса генерации, чтобы можно было отследить, какой промпт и настройки дали текст.
Наконец, повсюду добавьте ID и временные метки. Каждому элементу контента нужен стабильный content_id плюс created_at, updated_at и published_at. Это избавит от вопросов «какую версию мы утвердили?» и упростит аудит.
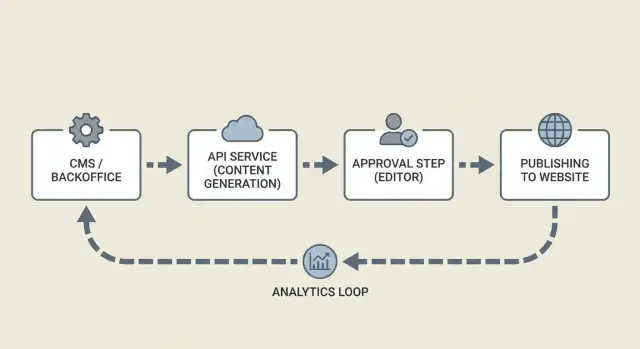
Обзор архитектуры: сервисы и их взаимодействие
Надёжный пайплайн делит работу на небольшие сервисы, которые передают понятные сообщения. Это держит CMS чистой, облегчает повторные попытки при ошибках и позволяет людям сосредоточиться на утверждениях.
На высоком уровне обычно есть четыре части:
- Generator service: получает бриф и возвращает черновик вместе с предложенными заголовком, структурами и метаданными.
- Approval UI: место, где редакторы читают, комментируют, просят правки и утверждают.
- Publisher worker: берёт утверждённый контент, обновляет CMS, планирует или публикует.
- Tracking store: фиксирует, что произошло (успехи, ошибки, временные метки) и позже собирает сигналы производительности.
То, как сервисы общаются, важнее, чем то, какие инструменты вы используете. Webhook‑ы или очередь полезны, чтобы медленные шаги (генерация, рендер изображений, публикация в CMS) не блокировали UI. Генератор должен отвечать ID, и каждый последующий шаг должен ссылаться на тот же ID.
Простой поток: бэкенд создаёт запрос контента, генератор возвращает черновик, редактор утверждает, а публикационный воркер подтверждает результат в CMS. Между шагами храните статус, чтобы можно было аккуратно восстановиться после сбоя.
Какие данные передаются между сервисами
Держите полезную нагрузку небольшой и предсказуемой. Например:
- Бриф (входные данные) плюс модель контента (требуемые поля)
- Черновой контент плюс заметки редактора по изменениям
- Инструкция на публикацию (публиковать сейчас или по расписанию)
- Чек‑лист публикации (CMS entry ID, slug, предупреждения)
Отслеживание и петли обратной связи
Трекинг — это больше, чем аналитика. Это ваша дорожная карта аудита.
Если публикация провалилась из‑за отсутствующего обязательного поля в CMS, запишите точную ошибку и переведите элемент в статус «Needs fixes». Если позже показатели покажут низкие клики, инициируйте целенаправленный запрос на ревизию (например, протестировать новый заголовок и meta description).
Пример: маркетологи ставят в очередь 20 FAQ по продукту. Черновики генерируются ночью, редакторы просматривают их утром, а воркер планирует публикацию. Лог показывает 18 успешных и 2 с ошибкой, потому что отсутствовала категория, — эти два возвращаются на быстрый фикс.
Пошагово: как построить конвейер от и до
Добавьте автоматические предварительные проверки
Убирайте форматирование, корректируйте тон и базовые SEO-параметры до того, как редактор откроет черновик.
Хороший пайплайн — это не про автоматическое написание, а про безопасную передачу одного и того же контента от идеи до публикации с понятными передачами и бумажным следом.
Начните с брифа, который можно повторно использовать
До любого API‑вызова создайте шаблон брифа. Делайте его коротким, чтобы люди его заполняли, но структурированным так, чтобы генератор не угадывал.
Хороший бриф обычно включает:
- Тему и единственный вопрос, на который отвечает пост
- Целевого читателя (что он уже знает)
- Тон (дружелюбный, нейтральный, экспертный)
- Целевую длину и формат (how‑to, глоссарий, новость)
- Необходимые SEO‑входы (основное ключевое слово, география, названия продуктов)
Храните бриф в CMS или БД, чтобы каждый черновик можно было отследить до запроса.
Генерируйте, валидируйте, ревьюйте, публикуйте
После сохранения брифа ваш бэкенд вызывает API генерации контента и сохраняет возвращённый черновик как новый элемент контента со статусом, например «Draft generated». Сохраняйте и отправленные входы, и полный ответ, чтобы позже можно было воспроизвести результат.
До того, как человек увидит черновик, прогоните быстрые автоматические проверки. Здесь команды часто экономят больше всего времени.
Держите проверки прагматичными:
- Наличие обязательных полей (title, description, slug, теги)
- Явные дубликаты (та же тема, тот же slug, почти идентичное вступление)
- Правила форматирования (есть заголовки, абзацы не гигантские, запрещённые фразы отсутствуют)
- Базовая SEO‑проверка (нет переспама ключевых слов, заголовки соответствуют содержанию)
- Требования к изображениям (существует промпт или выбран ассет)
Затем автоматически направьте черновик нужному рецензенту. Посты о продукте идут продукт‑оунеру; чувствительные темы — в отдельную очередь.
Когда рецензент утверждает, зафиксируйте версию. Заморозьте точный текст и метаданные, которые пойдут в публикацию, позволяя при этом создавать новые версии для будущих правок.
Наконец, публикуйте или планируйте. Записывайте результаты: время публикации, CMS entry ID и последующие сигналы эффективности. Если вы генерируете варианты CTA, сохраняйте, какой именно вариант ушёл в публикацию, чтобы позже сравнивать результаты.
Настройте ревью и утверждение так, чтобы не тормозить
Хороший процесс ревью — это быстрые решения с понятными причинами и надёжным бумажным следом.
Редакторы работают быстрее, когда видят, что изменилось, могут комментировать в контексте и отправлять целевые запросы на изменения без переписывания всего брифа. Если поддерживаются несколько раундов, система должна сохранять контекст.
Решите, что можно автоутверждать
Не всё требует одинаковой степени контроля. Сбережение человеческого внимания полезно там, где ошибка может навредить бренду.
Практические правила:
- Автоутверждать низкорисковые правки: орфография, форматирование, мелкие метаданные.
- Требовать редакторского просмотра для новых статей, новых утверждений или крупных переработок.
- Требовать экспертного ревью для медицинских, юридических, финансовых или безопасностных советов.
- Требовать бренд‑ревью для чувствительного тона или нейминга.
- Требовать факт‑чекинг, когда есть числа, сравнения или цитаты.
Реализуйте эти правила в статусной модели CMS. Например, сгенерированный черновик может автоматически перейти в «Needs review», но только роль редактора может переместить его в «Approved».
Обрабатывайте несколько раундов без хаоса
Рассматривайте каждую ревизию как новую версию и привязывайте утверждения к конкретной версии.
Шаблон, который масштабируется:
- Блокируйте утверждённую версию, пока правки делаются в новой ревизии.
- Привязывайте комментарии и запросы на изменения к конкретной версии.
- Устанавливайте максимум двух раундов рецензирования перед эскалацией в короткую живую дискуссию.
- Отслеживайте, кто что и когда утвердил.
Пример: писатель просит переписать материал после апдейта продукта. Генератор делает новый черновик. Редактор смотрит diff только по затронутым секциям, оставляет два inline‑комментария и ставит статус «Changes requested». Следующая версия возвращается с исправлениями и быстро утверждается.
Детали публикации: метаданные, изображения и планирование
Автоматизируйте передачу контента
Используйте API для создания предсказуемых workflow Draft → Review → Approved без ручного копирования.
Публикация — это момент, когда хороший черновик становится страницей, на которую кликают и читают. Важнейшие детали — метаданные, изображения и время выхода.
Метаданные: что генерируется, а что редактируется
Выберите один источник правды для каждого поля. Частая схема: бриф задаёт намерение, генератор предлагает варианты, а редактор принимает окончательное решение для всего, что видно пользователю.
Явно обрабатывайте эти поля: title, slug, meta description, canonical (если нужно), категория/теги, автор/дата. Пусть генератор предложит несколько опций, но сохраняйте версию, выбранную редактором, как публикуемую. Внутренние заметки (целевое ключевое слово, угол подачи, аудитория) храните отдельно от публичных метаданных.
Изображения: относитесь к ним как к контенту, а не вложениям
Изображения требуют собственного мини‑воркфлоу. Храните бриф для изображения рядом с брифом статьи, затем генерируйте, ревьюйте и публикуйте с явными статусами.
Простой поток:
- Напишите промпт для изображения, исходя из угла статьи (и бренд‑правил).
- Сгенерируйте несколько вариантов и выберите один.
- Подготовьте варианты нужных размеров (hero, social, thumbnail) и сожмите.
- Пропишите alt‑текст, который описывает изображение, а не содержит ключевое слово.
- Сохраните кредиты или заметки по лицензии и финальные ID файлов в CMS.
Формат публикации: Markdown, HTML или блоки CMS
Выбирайте формат, который соответствует вашей системе рендеринга. Markdown легко хранить и проверять. HTML даёт непосредственность, но сложнее безопасно редактировать. Блоки CMS хороши для сложных макетов, но усложняют работу генераторов.
Частый подход — хранить Markdown, конвертировать в HTML в момент публикации и держать структурированные метаданные (FAQ, ключевые тезисы, упоминания продуктов) в отдельных полях.
Планирование: часовые пояса, эмбарго и бэкфиллы
Планирование ломается, когда часовые пояса неясны. Храните publish_at в UTC, отдельно храните часовой пояс редактора для отображения и логируйте изменения расписания.
Эмбарго проще моделировать: контент может быть «approved», но заблокирован до окончания эмбарго. Для бэкфиллов (старые посты, которые вы мигрируете) держите original_published_at, чтобы показывать правильную дату без ломки сортировки или аналитики.
Пример: редактор утверждает пост в пятницу, планирует его на вторник 09:00 America/New_York и ставит эмбарго до анонса продукта. Конвейер держит материал готовым и меняет статус на «Published» только когда соблюдаются оба условия.
Частые ошибки и подводные камни
API‑конвейер может казаться автоматическим до того дня, когда он тихо опубликует что‑то сломанное. Большинство сбоев — не из‑за модели или CMS. Они из‑за отсутствия ограничений.
Одна из ошибок — частичная публикация. Пост в CMS создаётся и индексируется, но задача с героем не завершилась или шаг метаданных таймаутнулся. Читатели попадают на недоработанную страницу, а команда исправляет вручную. Трактуйте публикацию как единый релиз: проверьте обязательные поля, подтвердите готовность ассетов, затем публикуйте.
Ещё одна проблема — неясная ответственность. Если утверждение разделено и никто не отвечает, черновики накапливаются. Назначайте одного владельца на каждый элемент и давайте им явный шаг «утвердить» или «попросить правки».
Регерация тоже легко может навредить. Если вы регенерируете после того, как редактор сделал правки, вы можете перезаписать реальные правки. Блокируйте или снимайте снимок утверждённой версии и разрешайте регенерацию только в определённых статусах, например «Draft» или «Needs rewrite».
Частые проблемы:
- Публикация без прохода всех чеков (изображения, canonical, schema, категории).
- Нет единственного утверждающего или правила утверждения не задокументированы.
- Регенерация в неправильный момент и замена редакторских правок.
- Создание новых постов без проверки на похожие темы (каннибализация ключевых слов).
- Пропуск QA по заголовкам, slug и meta description.
Ограждения, которые спасают: лёгкий реестр тем, чтобы ранжировать дубликаты, финальный шаг QA, проверяющий длину заголовка и наличие обязательных метаданных, и безопасная операция публикации, которую можно повторить, чтобы временная ошибка не создала дубликат поста.
Краткий чек‑лист перед публикацией
Ускорьте индексацию после публикации
Отправляйте события публикации в IndexNow после утверждения и выхода материала в свет.
Мелкие упущения превращаются в большие раздражения: неправильный slug, пропущенные метаданные или черновик, который так и не был по‑настоящему утверждён. Короткий чек‑лист держит конвейер надёжным при большом объёме публикаций.
Готовность контента:
- Подтвердить, что есть бриф (аудитория, цель и действие, которое вы хотите, чтобы читатель совершил).
- Подтвердить, что публикуется самая новая утверждённая версия (ID версии и статус совпадают).
- Проверить заголовок и slug на читабельность и уникальность.
- Проверить сниппет поиска: meta description должен быть конкретным и соответствовать обещанию поста.
Технические проверки публикации:
- Валидировать изображения: корректные размеры, осмысленные имена файлов и описательные alt‑тексты.
- Запустить задачу публикации и сохранить ответ об успешности (CMS entry ID, финальный slug).
- Подтвердить детали расписания, включая часовой пояс.
- Убедиться, что теги для измерения прикреплены до выхода поста в эфир.
Пример: если редактор утверждает версию 7, а пайплайн публикует версию 6, всё выглядит нормально, пока кто‑то не заметит неправильный абзац в продакшене. Исправьте это, проверяя ID утверждённой версии и статус в том же шаге, который запускает публикацию.
Пример рабочего процесса и практические следующие шаги
Представьте небольшую маркетинговую команду, которая хочет публиковать регулярно, не тратя полнедели на копирование между инструментами. Они держат бэклог тем в CMS и стремятся к пяти черновикам в неделю. Цель — конвейер, который превращает бриф в черновик, маршрутизует на ревью и планирует с нужными метаданными.
Одна статья от и до:
- Создан бриф: маркетолог добавляет тему, аудиторию, ключевые слова и заметки в CMS.
- Сгенерирован черновик: воркер подхватывает бриф, вызывает API генерации и сохраняет черновик со статусом «Needs review».
- Редакторский просмотр: редактор правит в CMS и утверждает или просит правок.
- SEO и ассеты: проверяются заголовок, meta description и alt‑текст; присоединяется изображение.
- Планирование: пост планируется на конкретное время и переводится в «Scheduled».
Если редактор просит переработку, не перезаписывайте черновик вслепую. Создайте новую ревизию с явной причиной (например, «тон слишком коммерческий» или «нет примера»), затем снова запустите генерацию с заметками редактора как ограничениями. Храните обе версии, чтобы видеть, что изменилось и не повторять ту же ошибку.
После публикации логи превращают «кажется, сработало» в понятные дальнейшие шаги. Отслеживайте несколько сигналов для каждого поста: время от брифа до публикации (и где застряло), циклы правок, органические показы и клики, просмотры и конверсии CTA (если используете CTA), статус индексирования и ошибки публикации.
Следующие шаги: начните с малого. Автоматизируйте создание черновиков и изменение статусов сначала, затем добавляйте изображения, планирование и трекинг эффективности. Когда базовые вещи начнут стабильно работать, расширяйте на переводы и более быструю индексацию.
Если вы хотите сократить поверхность интеграции, GENERATED (generated.app) может выступить в роли API‑слоя для генерации и полировки текста, создания блог‑изображений и вариантов CTA с трекингом производительности, пока ваша CMS остаётся источником правды для утверждений и публикации. Он также поддерживает многоязычные рабочие процессы и опции быстрой индексации вроде IndexNow, что естественно вписывается, когда ваш конвейер уже отслеживает статусы и события публикации.