29 de nov. de 2025·8 min de leitura
Pipeline de conteúdo com API: uma arquitetura passo a passo
Construa um pipeline de conteúdo com API desde a ideia até a publicação: geração, revisão, aprovação, agendamento e monitoramento, com uma arquitetura simples que você pode adaptar.
Qual problema um pipeline de conteúdo resolve
Um pipeline de conteúdo é o conjunto de etapas que leva uma ideia de "devemos publicar isso" até uma página ao vivo. Normalmente inclui redação, edição, metadados, imagens, aprovações e publicação. Quando o pipeline está claro, todos sabem o que acontece a seguir e o trabalho não se perde em conversas espalhadas.
A maioria das equipes não perde tempo só escrevendo. Elas perdem tempo nas pequenas tarefas repetitivas em torno disso: copiar texto entre ferramentas, esperar feedback, corrigir formatação, checar o tamanho do título, adicionar alt text, enviar imagens nos tamanhos certos e agendar posts. Os mesmos erros também se repetem porque o processo fica na cabeça das pessoas.
Um pipeline baseado em API transforma essas tarefas repetidas em requisições previsíveis entre sistemas: seu CMS, seu backend e serviços que geram ou validam conteúdo. Isso não significa publicar sem supervisão. Significa que as partes chatas acontecem por padrão (criação de rascunho, formatação, sugestões de metadados, variantes de imagem, atualizações de status), enquanto humanos controlam o que vai ao ar.
Uma definição prática de "automático" se parece com isto:
- Rascunhos podem ser gerados e preparados automaticamente, mas a publicação só ocorre a partir de um status aprovado.
- Regras são aplicadas por padrão (campos obrigatórios, noções básicas de SEO), mas editores podem sobrescrever quando necessário.
- Mudanças são registradas automaticamente, mas a assinatura final continua humana.
Essa abordagem compensa quando você publica com frequência, reutiliza conteúdo em vários lugares ou quer saída consistente entre autores. Se você publica raramente e o processo já é simples, publicar manualmente pode ser mais rápido.
Exemplo: uma pequena equipe de marketing escreve updates de produto num headless CMS. Uma pessoa redige, outra edita e uma terceira cuida de imagens e agendamento. Com um fluxo via API, um novo rascunho pode ser criado a partir de um template, preenchido com metadados sugeridos e emparelhado automaticamente com variantes de imagem redimensionadas. O editor então foca em precisão, clareza e voz.
As etapas básicas e papéis
Um pipeline orientado por API funciona melhor quando todos usam as mesmas poucas etapas. Você quer estrutura suficiente para evitar caos, mas não tanta que publicar vire reuniões de status.
A maioria das equipes acaba com cinco etapas:
- Brief (o que escrever e por quê)
- Rascunho (primeira versão)
- Revisão (qualidade, marca e checagens factuais)
- Publicação (agendar e ir ao ar)
- Medir (ver o que funcionou e o que não funcionou)
Cada etapa deve ter um dono claro e produzir dados específicos para a próxima etapa.
Quem faz o quê
Papéis podem ser cargos ou simplesmente chapéus que as pessoas vestem. O que importa é que uma pessoa seja responsável em cada passo.
Uma divisão simples:
- Solicitante: define tópico, público, objetivo e restrições (tom, extensão, pontos obrigatórios).
- Editor: melhora clareza e estrutura, checa noções de SEO e sinaliza informações faltantes.
- Aprovador: aprova precisão, questões legais, de marca ou afirmações de produto.
- Publicador: agenda, adiciona metadados e envia para o site.
CMS vs serviço backend
Nesse arranjo, o CMS é onde o conteúdo vive e onde os humanos trabalham: rascunhos, comentários, aprovações e campos de publicação. O serviço backend é a camada de automação: chama APIs de geração, aplica regras, armazena logs e move itens pelos status.
Um modelo mental útil: o CMS é a fonte da verdade para o artigo, e o backend é o controlador de tráfego.
Ao longo das etapas, algumas coisas devem se mover de forma confiável: o brief, o texto do artigo, campos de SEO (título, descrição, palavras-chave), ativos (prompts de imagem e IDs finais), propriedade (quem está designado) e timestamps de status para acompanhamento.
Exemplo: um solicitante submete um brief curto no CMS. O backend pega esse brief, gera um rascunho e metadados sugeridos, e devolve tudo ao CMS para edição. Após aprovação, o publicador agenda. Depois, o backend registra desempenho para que o próximo brief seja mais específico.
Defina seu modelo de conteúdo e status
A automação funciona melhor quando cada peça de conteúdo é um objeto previsível, não um documento solto. Antes de automatizar geração, revisão e publicação, decida quais campos você armazena e o que significa "pronto" em cada etapa.
Comece com um objeto de conteúdo que possa viajar pelo seu sistema. Mantenha simples, mas completo o suficiente para que um editor revise sem procurar detalhes faltantes.
Um conjunto prático de campos:
- Título e slug (ou chave de URL)
- Roteiro (headings e pontos-chave)
- Corpo (conteúdo completo do artigo)
- Imagens (prompts, alt text, IDs finais)
- Metadados (descrição, tags, palavra-chave alvo, canonical, autor)
Status são a outra metade do modelo. Devem ser em linguagem simples, mutuamente exclusivos e amarrados a permissões. Um conjunto comum:
- Draft
- Em revisão
- Aprovado
- Agendado
- Publicado
Trate o status como um contrato entre humanos e automação. Ferramentas de geração podem escrever em Draft, mas apenas um editor (ou uma regra de aprovação definida) deve movê-lo para Aprovado. O agendamento deve armazenar um publish_at e permitir mudanças até que vá ao ar.
Histórico de revisões mantém a automação segura. Armazene um revision ID para cada mudança significativa, junto com quem a fez e por quê. Um registro útil inclui: valor anterior, novo valor, editor ID, timestamp e uma nota opcional como "corrigiu afirmação factual" ou "atualizou meta description". Se você usar uma ferramenta de geração como GENERATED, armazene também o generation request ID para rastrear qual prompt e configurações produziram o texto.
Finalmente, adicione IDs e timestamps em todo lugar. Cada item de conteúdo precisa de um content_id estável mais created_at, updated_at e published_at. Isso evita debates do tipo "qual versão aprovamos?" e facilita auditorias.
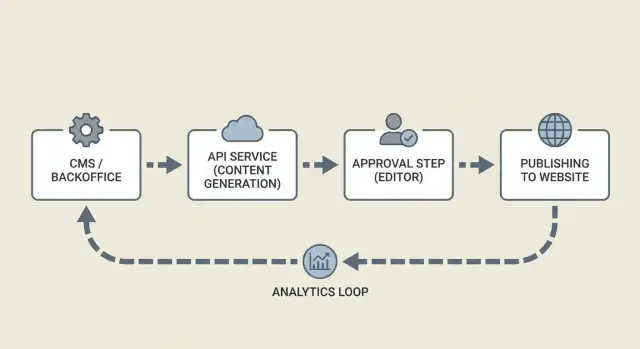
Visão geral da arquitetura: serviços e como se comunicam
Um pipeline confiável divide o trabalho em pequenos serviços que trocam mensagens claras. Isso mantém seu CMS limpo, facilita retry em falhas e mantém humanos focados em aprovações.
Em alto nível, você normalmente tem quatro partes:
- Serviço gerador: recebe um brief e retorna um rascunho mais título sugerido, headings e metadados.
- UI de aprovação: onde editores leem, comentam, pedem mudanças e aprovam.
- Worker de publicação: pega conteúdo aprovado, atualiza o CMS e então agenda ou publica.
- Armazenamento de rastreamento: registra o que aconteceu (sucesso, erros, timestamps) e depois captura sinais de desempenho.
Como os serviços se comunicam importa mais do que quais ferramentas você usa. Webhooks ou fila são comuns para que etapas lentas (geração, renderização de imagem, publicação no CMS) não bloqueiem a UI. O gerador deve responder com um ID, e cada etapa depois disso deve referenciar o mesmo ID.
Um fluxo simples: o backend cria uma solicitação de conteúdo, o gerador retorna um rascunho, um editor aprova e o publicador confirma o resultado no CMS. Entre cada etapa, armazene um status para que você possa retomar com segurança após uma falha.
Quais dados se movem entre serviços
Mantenha payloads pequenos e previsíveis. Por exemplo:
- Um brief (entradas) mais um modelo de conteúdo (campos obrigatórios)
- Conteúdo rascunho mais notas de alteração do editor
- Uma instrução de publicação (publicar agora vs horário agendado)
- Um recibo de publicação (ID de entrada no CMS, slug, avisos)
Rastreamento e loops de feedback
Rastreamento é mais que analytics. É sua trilha de auditoria.
Se a publicação falhar porque um campo obrigatório do CMS está faltando, registre o erro exato e mova o item para "Needs fixes." Se o desempenho depois mostrar poucas cliques, dispare uma solicitação de revisão focada (por exemplo, testar um novo título e meta description).
Exemplo: uma equipe de marketing enfileira 20 FAQs de produto. Rascunhos são gerados durante a noite, editores revisam pela manhã e o worker de publicação os agenda. O log mostra 18 bem-sucedidos e 2 falharam porque faltou um mapeamento de categoria, então esses dois voltam para um conserto rápido.
Passo a passo: construa o pipeline de ponta a ponta
Automatize suas entregas de conteúdo
Use a API para criar fluxos previsíveis Draft, Review, Approved sem copiar manualmente.
Um bom pipeline é menos sobre escrever automaticamente e mais sobre mover a mesma peça de conteúdo com segurança da ideia à publicação, com entregas claras e um rastro confiável.
Comece com um brief que você possa reusar
Antes de qualquer chamada de API, crie um template de brief. Mantenha curto para que as pessoas realmente preencham, mas estruturado o suficiente para que o gerador não precise adivinhar.
Um brief sólido geralmente inclui:
- Tópico e a pergunta única que o post responde
- Leitor alvo (o que já sabe)
- Tom (amigável, neutro, opinativo)
- Extensão e formato alvo (how-to, glossário, notícia)
- Entradas de SEO obrigatórias (palavra-chave primária, localização, nomes de produto)
Armazene o brief no seu CMS ou banco de dados para que cada rascunho seja rastreável até uma solicitação.
Gerar, validar, revisar, publicar
Uma vez salvo o brief, seu backend chama a API de geração de conteúdo e armazena o rascunho retornado como um novo item com um status claro (por exemplo, "Draft generated"). Salve tanto as entradas enviadas quanto a resposta completa para reproduzir o resultado depois.
Antes de um humano ver o rascunho, rode verificações rápidas automatizadas. Muitas vezes é aqui que equipes economizam mais tempo.
Mantenha as verificações práticas:
- Campos obrigatórios existem (título, descrição, slug, tags)
- Duplicados óbvios (mesmo tópico, mesmo slug, intro quase idêntica)
- Regras de formatação (headings presentes, parágrafos não enormes, frases/termos proibidos)
- Sanidade básica de SEO (sem stuffing de palavra-chave, headings coerentes com o conteúdo)
- Requisitos de imagem (existe um prompt ou um ativo selecionado)
Depois, roteie o rascunho automaticamente para o revisor certo. Posts de produto podem ir para um dono de produto; tópicos sensíveis podem ir para uma fila dedicada.
Quando um revisor aprova, trave a versão. Congele o texto e metadados exatos que vão ao ar, permitindo novas versões para edições futuras.
Finalmente, publique ou agende. Registre resultados como hora da publicação, ID de entrada no CMS e sinais de desempenho posteriores. Se você gerar variantes de CTA, armazene qual foi a que foi publicada para comparar resultados ao longo do tempo.
Configure revisão e aprovação sem desacelerar
Um bom fluxo de revisão é sobre decisões rápidas com razões claras e um rastro confiável.
Editores vão mais rápido quando conseguem ver o que mudou, comentar no contexto e enviar pedidos de mudança focados sem reescrever todo o brief. Se você suporta várias rodadas, faça o sistema carregar o contexto.
Decida o que pode ser aprovado automaticamente
Nem todo conteúdo precisa do mesmo nível de escrutínio. Poupe atenção humana para o que pode prejudicar sua marca.
Um conjunto prático de regras:
- Auto-aprovar correções de baixo risco como ortografia, formatação e pequenas alterações de metadados.
- Exigir revisão do editor para artigos novos, novas alegações ou reescritas significativas.
- Exigir revisão de especialista para conselhos médicos, legais, financeiros ou de segurança.
- Exigir revisão de marca para tom sensível ou nomes.
- Exigir checagem de fatos quando o conteúdo inclui números, comparações ou citações.
Aplique essas regras com gates no modelo de status do seu CMS. Por exemplo, um rascunho gerado pode mover de "Draft" para "Needs review" automaticamente, mas apenas um papel de editor pode empurrá-lo para "Approved."
Lide com múltiplas rodadas sem caos
Trate cada revisão como uma nova versão e mantenha aprovações vinculadas a uma versão específica.
Um padrão que escala:
- Trave a versão aprovada enquanto edições acontecem em uma nova revisão.
- Anexe comentários e pedidos de mudança a uma versão específica.
- Defina um máximo de duas rodadas de revisão antes de escalar para uma rápida discussão ao vivo.
- Acompanhe quem aprovou o quê e quando.
Exemplo: um redator pede reescrita após uma atualização de produto. O gerador produz um novo rascunho. O editor revisa um diff mostrando apenas as seções afetadas, deixa dois comentários inline e marca como "Changes requested." A versão seguinte volta com os pontos resolvidos e é aprovada rapidamente.
Detalhes de publicação: metadados, imagens e agendamento
Construa sobre uma única API de conteúdo
Produza posts de blog, notícias e páginas de glossário por meio de uma API única mantendo o CMS como fonte da verdade.
Publicar é onde bons rascunhos viram páginas que as pessoas clicam e leem. Os detalhes que mais importam são metadados, imagens e timing.
Metadados: decida o que é gerado vs editado
Escolha uma fonte da verdade para cada campo. Uma divisão comum: o brief define a intenção, o gerador sugere opções e um editor decide a versão final visível ao usuário.
Trate esses campos explicitamente: título, slug, meta description, canonical (se necessário), categoria/tags, autor/data. Deixe o gerador propor algumas opções, mas armazene a versão escolhida pelo editor como a publicável. Mantenha notas internas (palavra-chave alvo, ângulo, audiência) separadas dos metadados públicos.
Imagens: trate-as como conteúdo, não anexos
Imagens precisam de um pequeno workflow próprio. Armazene um brief de imagem junto ao brief do artigo, então gere, revise e publique com status claros.
Um fluxo simples:
- Escreva um prompt de imagem baseado no ângulo do artigo (mais regras de marca).
- Gere algumas opções e selecione uma.
- Redimensione para tamanhos necessários (hero, social, thumbnail) e comprima.
- Escreva alt text que descreva a imagem, não apenas a palavra-chave.
- Salve créditos ou notas de licença (se usar) e IDs finais no CMS.
Formato de publicação: Markdown, HTML ou blocos do CMS
Escolha um formato que combine com sua camada de renderização. Markdown é fácil de armazenar e revisar. HTML é direto, mas mais difícil de editar com segurança. Blocos do CMS são ótimos para layouts complexos, mas adicionam trabalho para geradores.
Uma abordagem comum é armazenar Markdown, converter para HTML no momento da publicação e manter metadados estruturados (FAQ, principais aprendizados, menções de produto) em campos separados.
Agendamento: fusos horários, embargos e backfills
O agendamento quebra quando fusos horários são vagos. Armazene publish_at em UTC, mantenha o fuso horário do editor separadamente para exibição e registre mudanças de agendamento.
Embargos são mais fáceis se você os modelar: conteúdo pode estar "aprovado" mas bloqueado de ir ao ar até o fim do embargo. Para backfills (posts antigos que você está migrando), mantenha um original_published_at para mostrar a data correta sem quebrar ordenação ou analytics.
Exemplo: um editor aprova um post na sexta, agenda para terça às 09:00 America/New_York e define um embargo até um anúncio de produto. O pipeline pode mantê-lo pronto e só mudar o status final para "Published" quando ambas as condições forem satisfeitas.
Erros comuns e armadilhas a evitar
Um pipeline por API pode parecer automático até o dia em que publica algo quebrado silenciosamente. A maioria das falhas não é sobre o modelo ou o CMS — é sobre guardrails ausentes.
Uma armadilha comum é publicação parcial. A entrada do CMS é criada e indexada, mas o job da imagem falha ou a etapa de metadados expira. Leitores chegam a uma página meia pronta e sua equipe corrige manualmente. Trate a publicação como um único release: valide campos obrigatórios, confirme que os ativos estão prontos e então publique.
Outra armadilha é propriedade obscura. Se aprovação for compartilhada mas ninguém for responsável, rascunhos se acumulam. Nomeie um dono por item de conteúdo e dê a ele uma ação clara de "aprovar" ou "pedir mudanças."
Regenerar também é fácil de usar errado. Se você regenerar depois que um editor fez mudanças, pode sobrescrever edições reais. Trave ou faça snapshot da versão aprovada e só permita regeneração em um status específico como "Draft" ou "Needs rewrite."
Problemas que aparecem frequentemente:
- Publicar sem gates de "todas as checagens passam" (imagens, canonical, schema, categorias).
- Sem um único aprovador, ou regras de aprovação que não estão documentadas.
- Regenerar no momento errado e substituir atualizações do editor.
- Criar posts novos sem checar tópicos similares (canibalização de keywords).
- Pular QA em títulos, slugs e meta descriptions.
Salvaguardas que evitam dor real: mantenha um registro leve de tópicos para identificar duplicados cedo, adicione uma checagem final de QA que verifique comprimento do título e metadados obrigatórios, e torne a operação de publicar segura para retentar para que uma falha temporária não gere posts duplicados.
Checklist rápido antes de publicar
Envie imagens sem passos extras
Gere, redimensione e aprimore imagens de blog com prompts, alt text e variantes consistentes.
Pequenas falhas viram grandes incômodos: slug errado, metadados faltando ou um rascunho que nunca foi realmente aprovado. Uma checklist curta mantém o pipeline confiável quando você publica em volume.
Prontidão do conteúdo:
- Confirme que existe um brief (público, objetivo e ação esperada do leitor).
- Confirme que está publicando a versão aprovada mais recente (ID da versão e status conferem).
- Revise título e slug quanto à legibilidade e unicidade.
- Verifique o snippet da busca: a meta description deve ser específica e corresponder à promessa do post.
Checagens técnicas de publicação:
- Valide imagens: tamanhos corretos, nomes de arquivos sensatos e alt text descritivo.
- Rode o job de publicação e armazene a resposta de sucesso (ID no CMS, slug final).
- Confirme detalhes de agendamento, incluindo fuso horário.
- Confirme que as tags de mensuração estão anexadas antes do post ir ao vivo.
Exemplo: se um editor aprova a versão 7 mas o pipeline publica a versão 6, parece tudo certo até alguém notar o parágrafo errado em produção. Evite isso checando o ID da versão aprovada e o status no mesmo passo que dispara a publicação.
Exemplo de fluxo e próximos passos práticos
Imagine uma pequena equipe de marketing que quer publicar com consistência sem gastar metade da semana copiando entre ferramentas. Eles mantêm um backlog de temas no CMS e miram cinco rascunhos por semana. O objetivo é um pipeline que transforme um brief em rascunho, roteie para revisão e agende com os metadados certos.
Um artigo de ponta a ponta:
- Brief criado: um marketeiro adiciona tópico, público, keywords e notas no CMS.
- Rascunho gerado: um worker pega o brief, chama a API de geração e salva o rascunho como "Needs review."
- Revisão do editor: o editor edita no CMS e aprova ou pede mudanças.
- SEO e ativos: título, meta description e alt text são checados; uma imagem é anexada.
- Publicação agendada: o post é agendado para um horário específico e movido para "Scheduled."
Se o editor pede reescrita, não sobrescreva o rascunho às cegas. Crie uma nova revisão com um motivo claro (por exemplo, "tom muito comercial" ou "falta exemplo") e então rode a geração novamente usando as notas do editor como restrições. Mantenha ambas as versões para ver o que mudou e evitar repetir o mesmo erro.
Depois da publicação, os logs transformam "achamos que funcionou" em ações claras. Acompanhe alguns sinais para cada post: tempo do brief até a publicação (e onde houve gargalo), ciclos de reescrita, impressões orgânicas e cliques, visualizações e conversões de CTAs (se você usar CTAs), status de indexação e erros de publicação.
Próximos passos: comece pequeno. Automatize criação de rascunhos e mudanças de status primeiro, depois adicione imagens, agendamento e rastreamento de desempenho. Quando o básico estiver estável, expanda para traduções e indexação mais rápida.
Se você quiser manter a superfície de integração pequena, GENERATED (generated.app) pode atuar como camada de API para gerar e polir textos, produzir imagens de blog e gerar variantes de CTA com rastreamento de desempenho, enquanto seu CMS permanece a fonte da verdade para aprovações e publicação. Também oferece suporte a workflows multilíngues e opções de indexação mais rápida como IndexNow, o que se encaixa naturalmente quando seu pipeline já está rastreando status e eventos de publicação.