29 nov. 2025·8 min de lecture
Pipeline de contenu avec une API : architecture étape par étape
Construisez un pipeline de contenu avec une API, de l'idée à la publication : génération, revue, approbation, programmation et suivi, avec une architecture simple et adaptable.
Quel problème résout un pipeline de contenu
Un pipeline de contenu est l'ensemble des étapes qui prend une idée de « on devrait publier ça » à une page en ligne. Il inclut généralement la rédaction, l'édition, les métadonnées, les images, les approbations et la publication. Quand le pipeline est clair, tout le monde sait ce qui suit et le travail ne disparaît plus dans des fils de discussion.
La plupart des équipes ne perdent pas du temps uniquement sur l'écriture. Elles perdent du temps sur les petites tâches répétées autour : copier le texte entre les outils, attendre des retours, corriger le formatage, vérifier la longueur d'un titre, ajouter du texte alternatif, téléverser des images aux bonnes tailles et programmer les publications. Les mêmes erreurs se répètent aussi parce que le processus vit dans la tête des gens.
Un pipeline basé sur une API transforme ces tâches répétées en requêtes prévisibles entre systèmes : votre CMS, votre backend et des services qui génèrent ou valident du contenu. Cela ne signifie pas publier sans contrôle. Cela signifie que les parties ennuyeuses se font par défaut (création de brouillon, formatage, suggestions de métadonnées, variantes d'image, mises à jour de statut), tandis que les humains contrôlent ce qui est diffusé.
Une définition pratique de « automatique » ressemble à ceci :
- Les brouillons peuvent être générés et préparés automatiquement, mais la publication n'a lieu qu'à partir d'un statut approuvé.
- Les règles sont appliquées par défaut (champs requis, bases SEO), mais les éditeurs peuvent outrepasser si besoin.
- Les changements sont journalisés automatiquement, mais la validation finale reste humaine.
Cette approche porte ses fruits quand vous publiez fréquemment, réutilisez du contenu à plusieurs endroits ou voulez une sortie cohérente entre les auteurs. Si vous publiez rarement et que le processus est déjà simple, la publication manuelle peut être plus rapide.
Exemple : une petite équipe marketing rédige des mises à jour produit dans un CMS headless. Une personne rédige, une autre édite, et une troisième gère les images et la planification. Avec un workflow API, un nouveau brouillon peut être créé depuis un modèle, rempli avec des métadonnées suggérées et apparié automatiquement à des variantes d'images redimensionnées. L'éditeur se concentre alors sur l'exactitude, la clarté et la voix.
Les étapes de base et les rôles
Un pipeline piloté par API fonctionne mieux lorsque tout le monde utilise les mêmes étapes simples. Il faut assez de structure pour éviter le chaos, sans que la publication ne devienne une série de réunions de statut.
La plupart des équipes finissent par avoir cinq étapes :
- Brief (quoi écrire et pourquoi)
- Brouillon (première version)
- Revue (qualité, marque et vérifications factuelles)
- Publication (programmation et mise en ligne)
- Mesure (voir ce qui a marché ou non)
Chaque étape doit avoir un responsable clair et produire des données spécifiques pour l'étape suivante.
Qui fait quoi
Les rôles peuvent être des intitulés de poste ou simplement des casquettes que portent les gens. Ce qui compte, c'est qu'une personne soit responsable à chaque étape.
Répartition simple :
- Demandeur : définit le sujet, l'audience, l'objectif et les contraintes (ton, longueur, points obligatoires).
- Éditeur : améliore la clarté et la structure, vérifie les bases SEO, signale les informations manquantes.
- Approbateur : valide l'exactitude, les aspects légaux, et les allégations produit ou marque.
- Publish-er : programme, ajoute les métadonnées et pousse vers le site.
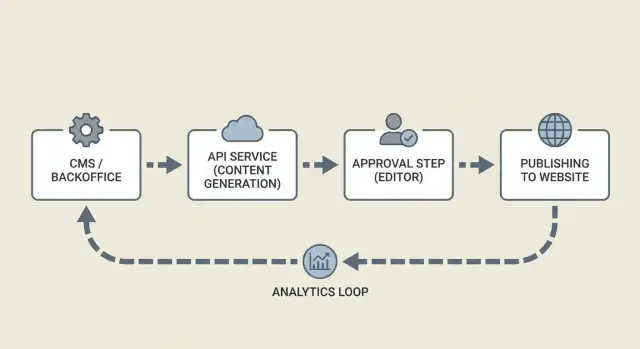
CMS vs service backend
Dans ce dispositif, le CMS est l'endroit où le contenu vit et où les humains travaillent : brouillons, commentaires, approbations et champs de publication. Le service backend est la couche d'automatisation : il appelle les API de génération, applique les règles, conserve les journaux et fait évoluer les éléments de statut.
Un modèle mental utile : le CMS est la source de vérité pour l'article, et le backend est le contrôleur de trafic.
À travers les étapes, quelques éléments doivent circuler de manière fiable : le brief, le texte de l'article, les champs SEO (titre, description, mots-clés), les assets (prompts d'image et IDs finaux), la propriété (qui est assigné) et les horodatages de statut pour le suivi.
Exemple : un demandeur soumet un court brief dans le CMS. Le backend le récupère, génère un brouillon et des métadonnées suggérées, puis renvoie le tout dans le CMS pour édition. Après approbation, le publish-er le programme. Plus tard, le backend enregistre les performances pour que le prochain brief soit plus précis.
Définissez votre modèle de contenu et vos statuts
L'automatisation marche mieux quand chaque élément de contenu est un objet prévisible, pas un document lâche. Avant d'automatiser la génération, la revue et la publication, décidez quels champs vous stockez et ce que signifie « fait » à chaque étape.
Commencez avec un objet de contenu qui peut voyager dans votre système. Gardez-le simple, mais suffisamment complet pour qu'un éditeur puisse le revoir sans chercher les informations manquantes.
Un ensemble pratique de champs :
- Titre et slug (ou clé d'URL)
- Plan (titres et points clés)
- Corps (contenu complet de l'article)
- Images (prompts, texte alternatif, IDs finaux)
- Métadonnées (description, tags, mot-clé cible, canonical, auteur)
Les statuts sont l'autre moitié du modèle. Ils doivent être en langage clair, mutuellement exclusifs et liés aux permissions. Un ensemble courant :
- Brouillon
- En revue
- Approuvé
- Programmé
- Publié
Traitez le statut comme un contrat entre humains et automatisation. Les outils de génération peuvent écrire dans Brouillon, mais seul un éditeur (ou une règle d'approbation définie) doit le passer à Approuvé. La programmation doit stocker un publish_at et permettre des modifications jusqu'à la mise en ligne.
L'historique des révisions rend l'automatisation sûre. Conservez un ID de révision pour chaque changement significatif, avec qui l'a fait et pourquoi. Un enregistrement utile inclut : valeur précédente, nouvelle valeur, ID de l'éditeur, horodatage et une note optionnelle comme « correction d'une affirmation factuelle » ou « mise à jour de la meta description ». Si vous utilisez un outil de génération comme GENERATED, conservez aussi l'ID de requête de génération afin de tracer quel prompt et quels paramètres ont produit le texte.
Enfin, ajoutez des IDs et des horodatages partout. Chaque élément de contenu a besoin d'un content_id stable ainsi que created_at, updated_at et published_at. Cela évite les débats du type « quelle version avons-nous approuvée ? » et facilite les audits.
Vue d'ensemble de l'architecture : services et communications
Un pipeline fiable répartit le travail en petits services qui passent des messages clairs. Cela garde votre CMS propre, rend les échecs plus faciles à relancer et permet aux humains de se concentrer sur les approbations.
À un haut niveau, on trouve généralement quatre parties :
- Service de génération : reçoit un brief et renvoie un brouillon avec titre, rubriques et métadonnées suggérés.
- Interface d'approbation : où les éditeurs lisent, commentent, demandent des modifications et approuvent.
- Worker de publication : prend le contenu approuvé, met à jour le CMS, puis programme ou publie.
- Magasin de suivi : enregistre ce qui s'est passé (succès, erreurs, horodatages) et capture plus tard les signaux de performance.
La façon dont les services communiquent importe plus que les outils choisis. Les webhooks ou une file d'attente sont courants pour que les étapes lentes (génération, rendu d'image, publication CMS) ne bloquent pas l'interface. Le générateur devrait répondre avec un ID, et chaque étape suivante devrait se référer au même ID.
Un flux simple : le backend crée une requête de contenu, le générateur renvoie un brouillon, un éditeur l'approuve, et le publish-er confirme le résultat dans le CMS. Entre chaque étape, stockez un statut pour pouvoir reprendre proprement après un crash.
Quelles données circulent entre services
Gardez les payloads petits et prévisibles. Par exemple :
- Un brief (inputs) plus un modèle de contenu (champs requis)
- Contenu du brouillon plus notes de modification de l'éditeur
- Instruction de publication (publier maintenant vs heure programmée)
- Reçu de publication (ID d'entrée CMS, slug, avertissements)
Suivi et boucles de rétroaction
Le suivi est plus que de l'analytics. C'est votre piste d'audit.
Si la publication échoue parce qu'un champ CMS requis manque, enregistrez l'erreur exacte et déplacez l'élément en « Nécessite des corrections ». Si les performances montrent plus tard peu de clics, déclenchez une demande de révision ciblée (par exemple, tester un nouveau titre et une nouvelle meta description).
Exemple : une équipe marketing met en file 20 FAQ produit. Les brouillons sont générés la nuit, les éditeurs révisent le matin, et le worker de publication les programme. Le log montre 18 réussites et 2 échecs parce qu'un mapping de catégorie manquait ; ces deux éléments sont renvoyés pour une correction rapide.
Étape par étape : construire le pipeline de bout en bout
Accélérez l'indexation après publication
Poussez les événements de publication vers IndexNow une fois le contenu approuvé et en ligne.
Un bon pipeline vise moins l'auto-rédaction que le fait de faire circuler le même contenu en toute sécurité, de l'idée à la publication, avec des passations claires et une trace.
Commencez par un brief réutilisable
Avant tout appel API, créez un modèle de brief. Gardez-le court pour que les gens le remplissent, mais structuré pour que le générateur n'ait pas à deviner.
Un brief solide inclut généralement :
- Sujet et question unique à laquelle l'article répond
- Lecteur cible (ce qu'il sait déjà)
- Ton (amical, neutre, assertif)
- Longueur et format ciblés (how-to, glossaire, news)
- Entrées SEO requises (mot-clé principal, localisation, noms de produits)
Stockez le brief dans votre CMS ou base de données pour que chaque brouillon soit traçable jusqu'à une demande.
Générer, valider, relire, publier
Une fois le brief enregistré, votre backend appelle l'API de génération de contenu et stocke le brouillon retourné comme nouvel élément de contenu avec un statut clair (par exemple, « Brouillon généré »). Sauvez à la fois les entrées envoyées et la réponse complète pour pouvoir reproduire le résultat plus tard.
Avant qu'un humain ne le voie, lancez des vérifications automatiques rapides. C’est souvent là que les équipes gagnent le plus de temps.
Gardez les contrôles pratiques :
- Les champs requis existent (titre, description, slug, tags)
- Doublons évidents (même sujet, même slug, intro quasi identique)
- Règles de formatage (présence de titres, paragraphes pas trop longs, phrases interdites)
- Sanité SEO basique (pas de bourrage de mots-clés, titres cohérents avec le contenu)
- Exigences d'image (un prompt existe ou un asset est sélectionné)
Puis orientez automatiquement le brouillon vers le bon relecteur. Les articles produit peuvent aller au responsable produit ; les sujets sensibles à une file dédiée.
Quand un relecteur approuve, verrouillez la version. Figez le texte et les métadonnées exacts qui partiront, tout en autorisant de nouvelles versions pour des éditions futures.
Enfin, publiez ou programmez. Enregistrez des résultats comme l'heure de publication, l'ID d'entrée CMS et les signaux de performance ultérieurs. Si vous générez des variantes de CTA, enregistrez celle qui a été publiée pour comparer les résultats dans le temps.
Mettez en place la revue et l'approbation sans ralentir
Un bon flux de relecture favorise des décisions rapides avec des raisons claires et une piste fiable.
Les éditeurs vont plus vite quand ils voient ce qui a changé, peuvent commenter dans le contexte et envoyer des demandes de modification ciblées sans réécrire le brief entier. Si vous supportez plusieurs rounds, faites en sorte que le système conserve le contexte.
Décidez ce qui peut être auto-approuvé
Tout n'a pas besoin du même niveau de contrôle. Préservez l'attention humaine pour ce qui peut nuire à votre marque.
Un jeu de règles pratique :
- Auto-approuver les corrections à faible risque comme l'orthographe, le formatage et les petits ajustements de métadonnées.
- Exiger une revue éditoriale pour les nouveaux articles, nouvelles affirmations ou grosses réécritures.
- Exiger un examen métier pour le médical, le légal, la finance ou les conseils de sécurité.
- Exiger une revue marque pour le ton sensible ou la dénomination.
- Exiger des vérifications factuelles quand le contenu contient des chiffres, des comparaisons ou des citations.
Appliquez ces règles avec des verrous dans le modèle de statuts du CMS. Par exemple, un brouillon généré peut passer automatiquement de « Brouillon » à « Nécessite révision », mais seul un rôle éditeur peut le pousser à « Approuvé ».
Gérez plusieurs tours sans chaos
Traitez chaque révision comme une nouvelle version et liez les approbations à une version spécifique.
Un schéma qui scale :
- Verrouillez la version approuvée pendant que les modifications se font sur une nouvelle révision.
- Attachez commentaires et demandes de changement à une version précise.
- Limitez à deux tours de revue avant d'escalader vers une discussion rapide en direct.
- Suivez qui a approuvé quoi et quand.
Exemple : un rédacteur demande une réécriture après une mise à jour produit. Le générateur produit un nouveau brouillon. L'éditeur revoit un diff montrant uniquement les sections affectées, laisse deux commentaires en ligne et marque « Modifications demandées ». La version suivante corrige les points et est approuvée rapidement.
Détails de publication : métadonnées, images et programmation
Publiez des images sans étapes supplémentaires
Générez, redimensionnez et peaufinez les images de blog avec des prompts, du texte alternatif et des variantes cohérentes.
La publication est l'étape où de bons brouillons deviennent des pages que les gens cliqueront et liront. Les détails qui comptent le plus sont les métadonnées, les images et le timing.
Métadonnées : décider ce qui est généré vs édité
Choisissez une source de vérité pour chaque champ. Une répartition commune : le brief fixe l'intention, le générateur propose des options, et un éditeur tranche sur ce qui est visible par l'utilisateur.
Gérez explicitement ces champs : titre, slug, meta description, canonical (si nécessaire), catégorie/tags, auteur/date. Laissez le générateur proposer quelques options, mais enregistrez la version choisie par l'éditeur comme version publiable. Gardez les notes internes (mot-clé cible, angle, audience) séparées des métadonnées publiques.
Images : traitez-les comme du contenu, pas des pièces jointes
Les images ont besoin de leur mini-workflow. Stockez un brief d'image à côté du brief article, puis générez, révisez et publiez avec des statuts clairs.
Flux simple :
- Rédiger un prompt d'image selon l'angle de l'article (plus règles de marque).
- Générer quelques options et en sélectionner une.
- Redimensionner aux tailles requises (hero, social, vignette) et compresser.
- Rédiger un texte alternatif qui décrit l'image, pas le mot-clé.
- Enregistrer les crédits ou notes de licence (si utilisés) et les IDs finaux dans le CMS.
Format de publication : Markdown, HTML ou blocs CMS
Choisissez un format qui correspond à votre système de rendu. Le Markdown est facile à stocker et à relire. L'HTML est direct mais plus risqué à éditer. Les blocs CMS sont parfaits pour les mises en page complexes mais compliquent la génération.
Une approche courante est de stocker en Markdown, convertir en HTML au moment de la publication et conserver les métadonnées structurées (FAQ, points clés, mentions produit) dans des champs séparés.
Programmation : fuseaux horaires, embargo et backfills
La programmation casse quand les fuseaux horaires sont vagues. Stockez publish_at en UTC, conservez le fuseau horaire de l'éditeur séparément pour l'affichage, et journalisez les modifications de planning.
Les embargo sont plus simples si vous les modélisez : le contenu peut être « approuvé » mais bloqué pour la mise en ligne jusqu'à la fin de l'embargo. Pour les backfills (anciens articles migrés), conservez un original_published_at pour afficher la bonne date sans perturber le tri ou l'analytics.
Exemple : un éditeur approuve un article le vendredi, le programme pour mardi 09:00 America/New_York et définit un embargo jusqu'à une annonce produit. Le pipeline le garde prêt et ne bascule le statut final en « Publié » que lorsque les conditions sont réunies.
Erreurs courantes et pièges à éviter
Un pipeline API peut sembler automatique jusqu'au jour où il publie discrètement quelque chose de cassé. La plupart des échecs ne viennent pas du modèle ou du CMS, mais de l'absence de garde-fous.
Un piège courant est la publication partielle. L'article CMS est créé et indexé, mais la tâche d'image échoue ou l'étape métadonnées expire. Les lecteurs tombent sur une page incomplète et l'équipe répare à la main. Traitez la publication comme une seule mise en production : validez les champs requis, confirmez que les assets sont prêts, puis publiez.
Autre piège : propriété floue. Si l'approbation est partagée et que personne n'est responsable, les brouillons s'entassent. Nommez un propriétaire par élément de contenu et donnez-lui une action claire « approuver » ou « demander des modifications ».
La régénération est facile à mal utiliser. Si vous régénérez après qu'un éditeur a fait des modifications, vous pouvez écraser de vraies corrections. Verrouillez ou snapshottez la version approuvée, et n'autorisez la régénération que dans un statut spécifique comme « Brouillon » ou « Nécessite réécriture ».
Problèmes fréquents :
- Publication sans verrous « tous les contrôles passés » (images, canonical, schema, catégories).
- Pas d'approbateur unique, ou règles d'approbation non documentées.
- Régénération au mauvais moment remplaçant les mises à jour de l'éditeur.
- Création de nouveaux articles sans vérifier les sujets similaires (cannibalisation de mots-clés).
- Omission de la QA sur titres, slugs et meta descriptions.
Garde-fous utiles : conservez un registre léger des sujets pour repérer les doublons tôt, ajoutez une étape QA finale qui vérifie la longueur du titre et les métadonnées requises, et faites en sorte que l'opération de publication soit sûre à relancer pour qu'une erreur temporaire ne crée pas de doublons.
Checklist rapide avant de publier
Ajoutez des contrôles préalables automatisés
Nettoyez le formatage, le ton et les bases SEO avant même que les éditeurs ouvrent le brouillon.
Les petites erreurs deviennent de grandes nuisances : mauvais slug, métadonnées manquantes ou brouillon jamais vraiment approuvé. Une courte checklist maintient la fiabilité du pipeline quand vous publiez en volume.
Prêt du contenu :
- Confirmer qu'un brief existe (audience, objectif et l'action attendue du lecteur).
- Confirmer que vous publiez la dernière version approuvée (ID de version et statut concordent).
- Relire le titre et le slug pour lisibilité et unicité.
- Vérifier l'extrait de recherche : la meta description doit être précise et correspondre à la promesse de l'article.
Contrôles techniques de publication :
- Valider les images : bonnes tailles, noms de fichiers sensés et texte alternatif descriptif.
- Exécuter le job de publication et conserver la réponse de succès (ID d'entrée CMS, slug final).
- Confirmer les détails de programmation, y compris le fuseau horaire.
- Confirmer l'attachement des balises de mesure avant la mise en ligne.
Exemple : si un éditeur approuve la version 7 mais que le pipeline publie la version 6, tout semble correct jusqu'à ce que quelqu'un repère le mauvais paragraphe en production. Évitez ceci en vérifiant l'ID de version approuvée et le statut au même moment que le déclenchement de la publication.
Exemple de workflow et prochaines étapes pratiques
Imaginez une petite équipe marketing qui veut publier de façon régulière sans passer la moitié de la semaine à copier entre outils. Ils gardent un backlog de sujets dans leur CMS et visent cinq brouillons par semaine. L'objectif est un pipeline qui transforme un brief en brouillon, le route pour revue et le programme avec les bonnes métadonnées.
Un article de bout en bout :
- Brief créé : un marketeur ajoute un sujet, audience, mots-clés et notes dans le CMS.
- Brouillon généré : un worker récupère le brief, appelle l'API de génération et enregistre le brouillon comme « Nécessite révision ».
- Relecture éditoriale : l'éditeur édite dans le CMS et approuve ou demande des modifications.
- SEO et assets : titre, meta description et texte alternatif sont vérifiés ; une image est attachée.
- Programmation : l'article est programmé pour une heure donnée et passe en « Programmé ».
Si l'éditeur demande une réécriture, n'écrasez pas le brouillon aveuglément. Créez une nouvelle révision avec une raison claire (par exemple, « ton trop commercial » ou « exemple manquant »), puis relancez la génération en utilisant les notes de l'éditeur comme contrainte. Conservez les deux versions pour voir ce qui a changé et éviter de répéter l'erreur.
Après publication, les logs transforment le « on pense que ça a marché » en actions claires. Suivez quelques signaux pour chaque article : temps du brief à la publication (et où ça a bloqué), cycles de réécriture, impressions organiques et clics, vues et conversions des CTA (si vous en utilisez), statut d'indexation et erreurs de publication.
Prochaines étapes : commencez petit. Automatisez d'abord la création de brouillons et les changements de statut, puis ajoutez images, programmation et suivi de performance. Une fois les bases stables, étendez aux traductions et à l'indexation plus rapide.
Si vous voulez garder la surface d'intégration petite, GENERATED (generated.app) peut jouer le rôle de couche API pour générer et polir du texte, produire des images de blog et créer des variantes de CTA avec suivi de performance, tandis que votre CMS reste source de vérité pour les approbations et la publication. Il prend aussi en charge les workflows multilingues et des options d'indexation plus rapides comme IndexNow, ce qui s'intègre naturellement une fois que votre pipeline suit déjà les statuts et les événements de publication.