07. Aug. 2025·8 Min. Lesezeit
Im großen Maßstab veröffentlichen ohne Indexierungsverzögerungen: eine praktische Checkliste
In großem Maßstab veröffentlichen ohne Indexierungsverzögerungen: eine einfache Checkliste zu Crawl-Budget, internen Links, Sitemap-Hygiene und verantwortungsvollen Indexing-Pings, damit Seiten schneller gefunden werden.
Wie Indexierungsverzögerungen aussehen, wenn Sie viel veröffentlichen
Indexierungsverzögerungen folgen meist dem gleichen Muster: Sie veröffentlichen, die Seite ist live, aber sie erscheint Tage (manchmal Wochen) nicht in der Suche. Bei niedrigen Volumina fällt diese Verzögerung leicht nicht auf. Wenn Sie Dutzende URLs pro Tag liefern, wird der Rückstau offensichtlich, weil neue Seiten schneller entstehen, als sie in den Index aufgenommen werden.
Ein gängiges Zeichen ist ein Search Console-Status wie "Crawled, currently not indexed." Das bedeutet, ein Bot hat die URL besucht, aber sie nicht als durchsuchbares Ergebnis gespeichert. Ein anderes Muster: nur ein Teil Ihrer neuesten Seiten wird indexiert, während ältere Bereiche der Site normal weiterlaufen.
Sobald Sie von 10 Seiten auf 1.000+ springen, müssen Crawler entscheiden, wo sie Zeit investieren. Wenn Ihre Site viele ähnliche URLs produziert (Duplikate, dünne Seiten, Parameter-Varianten), können Bots Besuche an den falschen Stellen verschwenden. Die Seiten, die Ihnen wichtig sind, müssen warten.
Häufige Ursachen für das hohe Volumen an "crawled but not indexed"-Problemen sind:
- Die Seite wirkt zu ähnlich zu bestehenden Seiten (wiederverwendete Templates, wiederkehrende Einstiege, fast identische Themen).
- Die Seite wirkt unbedeutend (wenige interne Links, tief in der Paginierung vergraben).
- Die Seite sendet gemischte technische Signale (falsches Canonical, versehentliches
noindex, blockierte Ressourcen). - Die Site erzeugt zu viele URLs mit geringem Wert (Filter, Tracking-Parameter, facettierte Navigation).
- Der Inhalt befriedigt die Suchanfrage nicht (dünn, veraltet oder ohne wichtige Details).
Ein schneller Weg, Qualitätsprobleme von Discovery-Problemen zu unterscheiden, ist, eine kleine Stichprobe neuer URLs zu prüfen (z. B. 20) und zwei Fragen zu stellen.
Erstens: Kann ein Crawler sie leicht entdecken? Bestätigen Sie, dass die URL in Ihrer XML-Sitemap steht, mindestens einen prominenten internen Link hat, 200 OK zurückgibt und nicht durch robots-Regeln blockiert ist.
Zweitens: Ist sie nach dem Entdecken das Indexieren wert? Achten Sie auf echte Einzigartigkeit (nicht nur eine Umformulierung einer bestehenden Seite), eine klare Intent-Übereinstimmung (sie beantwortet eine echte Frage) und ausreichenden Umfang (Konkretes und Beispiele, nicht nur ein Template).
Wenn die Mehrheit Ihrer Stichprobe bei der ersten Frage durchfällt, haben Sie ein Discovery-System-Problem. Wenn sie die Discovery-Frage bestehen, aber bei der zweiten durchfallen, haben Sie ein Qualitäts- und Duplikationsproblem. Beheben Sie die richtige Ursache, und der Rückstau schrumpft in der Regel schnell.
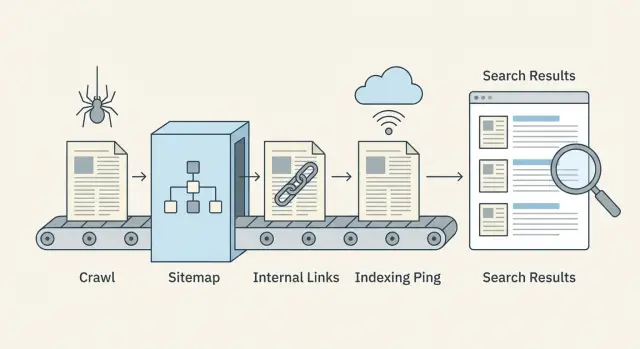
Der Crawl-to-Index-Fluss in einfachen Worten
Veröffentlichen macht eine Seite nicht sofort durchsuchbar. Suchmaschinen führen sie durch eine Pipeline, und Verzögerungen können an jedem Schritt auftreten.
Discovery, Crawling und Indexierung (was sie bedeuten)
Discovery ist, wenn eine Suchmaschine erfährt, dass eine URL existiert. Das geschieht meist über interne Links, Ihre XML-Sitemap oder eine externe Erwähnung.
Crawling ist, wenn ein Bot die URL besucht und herunterlädt, was er sieht (HTML, wichtige Ressourcen und manchmal zusätzliche verlinkte URLs). Crawling ist begrenzt durch Zeit und Aufmerksamkeit, daher werden einige Seiten spät oder selten besucht.
Indexierung ist, wenn die Suchmaschine entscheidet, ob sie die Seite speichert und für welche Suchanfragen sie angezeigt wird. Eine gecrawlte Seite wird nicht automatisch indexiert.
Der Ablauf sieht so aus:
- Die Suchmaschine findet die URL (Discovery)
- Ein Bot holt die Seite (Crawl)
- Die Seite wird bewertet und entweder gespeichert oder übersprungen (Index)
- Rankings aktualisieren sich im Laufe der Zeit, wenn Signale sich ansammeln
Wo Verzögerungen üblicherweise auftreten
Die meisten Verzögerungen passieren, bevor der Bot die Seite erreicht, oder direkt nachdem er sie gecrawlt hat.
Discovery-Verzögerungen zeigen sich, wenn neue Seiten verwaist sind (keine Links darauf zeigen) oder wenn Sitemaps veraltet sind.
Crawl-Verzögerungen entstehen oft dadurch, dass Crawls auf URLs mit geringem Wert verschwendet werden (duplizierte Pfade, facettierte Seiten, Parameter-Spam) oder durch langsame Server-Antworten.
Indexierungsverzögerungen treten auf, wenn Seiten zu ähnlich zu anderen erscheinen, dünne Inhalte haben, gemischte Signale senden (Canonical auf eine andere Seite zeigen, versehentliches noindex) oder wichtigen Inhalt spät laden.
Signale, die Sie schnell vs. langsam ändern können
Schnelle Hebel sind meist technisch und strukturell: stärkere interne Links von bereits gecrawlten Seiten, genaue Sitemaps, weniger Crawl-Fallen, bessere Antwortzeiten und verantwortungsvolle Indexing-Pings, wenn sie sinnvoll sind.
Langsamere Hebel brauchen Zeit: Gesamtqualität der Site, Konsistenz, verdiente Links und langfristige Engagement-Signale.
Was wöchentlich messen
Sie brauchen kein komplexes Dashboard, um Probleme früh zu erkennen. Verfolgen Sie wöchentlich eine kleine Reihe von Kennzahlen:
- Neu veröffentlichte URLs vs. neu indexierte URLs
- Medianzeit vom Veröffentlichen bis zum ersten Crawl
- Crawl-Fehler und langsame Antworten (5xx, Timeouts)
- Anteil von "Discovered, currently not indexed" und "Crawled, currently not indexed"
- Sitemap-Abdeckung: URLs in der Sitemap vs. tatsächlich indexierbare URLs
Crawl-Budget: verschwenden Sie Crawls nicht an URLs mit geringem Wert
Volume beim Veröffentlichen bedeutet nicht nur, gute Seiten zu erstellen. Es bedeutet auch, es Crawlern leicht zu machen, ihre Zeit auf den Seiten zu verbringen, die wichtig sind.
Crawl-Budget wird verschwendet, wenn Bots viele Versionen desselben Inhalts finden oder viele Seiten mit wenig Wert. Typische Übeltäter sind URL-Parameter (Sortierung, Tracking-Tags), facettierte Filter, Tag-Archive, Druckansichten und Seiten, die sich kaum unterscheiden.
Anzeichen, dass Sie Crawl-Budget verschwenden:
- Viele URLs, die sich nur durch kleine Parameter unterscheiden (wie
?sort=oder?ref=) - Filter, die endlose Kombinationen erzeugen (color=, size=, brand=)
- Dünne Seiten, die auf vielen URLs wiederholt werden
- Redirect-Ketten (mehrere Hops vor der finalen Seite)
- Spitzen in 404/500-Fehlern oder Timeouts in den Server-Logs
Geschwindigkeit und Fehler beeinflussen direkt, wie oft Bots zurückkommen. Ist Ihre Site langsam oder liefert häufig Fehler, fahren Crawler zurück, um Ressourcen zu sparen. Das Beheben von 5xx-Fehlern, Reduzieren von Timeouts und Verbessern der Antwortzeiten kann die Crawl-Frequenz stärker erhöhen als noch mehr Seiten zu veröffentlichen.
Das Blockieren von Bereichen mit geringem Wert kann helfen, aber tun Sie es mit Bedacht. Blockieren Sie wirklich nutzlose Bereiche (unendliche Filterkombinationen, interne Suchergebnisse, Kalenderseiten, die endlose URLs erzeugen). Blockieren Sie nicht Seiten, die Sie indexiert haben möchten, nur weil sie neu sind. Wenn eine Seite später ranken soll, muss sie jetzt crawlbar sein.
Duplikate reduzieren, ohne Ihr CMS zu verändern
Selbst wenn Sie die URL-Erzeugung nicht leicht ändern können, können Sie Duplikatsignale reduzieren:
- Fügen Sie Canonical-Tags hinzu, sodass Parameter-Versionen auf die Haupt-URL verweisen.
- Verwenden Sie konsistente interne Links, die immer auf die saubere URL zeigen.
- Entfernen Sie parameterisierte URLs aus Ihrer XML-Sitemap.
- Fügen Sie robots.txt-Regeln für offensichtliche Junk-Muster hinzu (nur wenn Sie sicher sind).
- Normalisieren Sie Redirects, sodass alte Varianten in einem Schritt auflösen.
Beispiel: Eine E‑Commerce-Kategorie könnte als /shoes existieren, plus /shoes?sort=price und /shoes?color=black. Halten Sie /shoes indexierbar und intern verlinkt. Kanonisieren Sie die Varianten zurück auf /shoes und halten Sie die Varianten aus der Sitemap heraus. Das lenkt Crawler zur richtigen Seite und weg von Schleifen.
Interne Verlinkung, die neuen Seiten beim Entdecken hilft
Wenn Sie viel veröffentlichen, sind interne Links Ihr schnellstes Discovery-Signal. Suchmaschinen können nur das crawlen, was sie finden. Wenn neue URLs nicht von Seiten verlinkt werden, die bereits gecrawlt werden, bleiben sie oft unbemerkt, selbst wenn Ihre Sitemap perfekt ist.
Cluster bauen, die neue Seiten natürlich sichtbar machen
Denken Sie in Themen-Clusters: eine starke Kernseite, die relevant bleibt (ein Leitfaden, Kategorie-Seite, Glossarbegriff oder FAQ), plus unterstützende Artikel, die spezifische Fragen beantworten. Wenn Sie einen neuen unterstützenden Artikel hinzufügen, verlinken Sie ihn von der Kernseite und von 1–2 verwandten unterstützenden Artikeln. Linken Sie ihn dann zurück zur Kernseite.
Beispiel: Eine Kernseite wie "Email marketing basics" kann zu neuen Stücken wie "Welcome email examples" und "How to clean your list" verlinken. Diese neuen Seiten verlinken zurück zur Kernseite, so dass Crawler durch das Cluster weiterlaufen statt stehenzubleiben.
Verwenden Sie ein einfaches New-Content-Hub
Eine "New content"-Hub-Seite hilft, wenn Sie täglich oder stündlich veröffentlichen. Sie muss nicht aufwändig sein. Sie muss nur leicht über Navigation oder Homepage erreichbar und automatisch aktualisiert werden.
Halten Sie sie aufgeräumt: zeigen Sie aktuelle Beiträge nach Thema und vermeiden Sie Endlos-Scrollen, das immer weiter wächst. So ein Hub wird zu einem zuverlässigen Ort, den Crawler regelmäßig besuchen.
Anchor-Text ist wichtig, aber nur sinnvoll eingesetzt. Verwenden Sie klare Wörter, die die Seite beschreiben ("welcome email checklist"), keine vagen Labels ("click here") und kein Keyword-Stuffing.
Für die erste Woche nach Veröffentlichung funktioniert eine einfache Regel gut:
- Verlinken Sie jede neue Seite von mindestens 2 bereits gecrawlten Seiten (ein Hub- oder Kategorie-Seite zählt als eine).
- Fügen Sie 1 kontextuellen Link aus einem eng verwandten älteren Artikel hinzu.
- Verlinken Sie zurück zur Kern-Themenseite, damit das Cluster verbunden bleibt.
- Halten Sie die Anzahl der Links moderat, damit wichtige Links herausstechen.
Achten Sie auf verwaiste Seiten (Seiten ohne interne Links). Ein praktischer Weg, sie zu finden, ist, Ihre veröffentlichte URL-Liste (oder Sitemap-URLs) mit dem abzugleichen, was ein Site-Crawl als "intern verlinkt" meldet. Jede URL ohne interne Links ist ein Discovery-Risiko.
Wenn Ihr Publishing-System es unterstützt, bauen Sie interne Links in den Veröffentlichungsprozess ein, damit neue Seiten nicht am ersten Tag allein gelassen werden.
Sitemaps, die bei großem Umfang sauber bleiben
Ship content through your API
Serve blogs, news, and glossary content via API so every new URL ships consistently.
Bei hohem Volumen wird Ihre XML-Sitemap weniger zu einem "Nice-to-have" und mehr zu einem Bedienfeld. Sie sagt Suchmaschinen, was sich geändert hat und was wichtig ist.
Was enthalten (und was rauslassen)
Ihre Sitemap sollte nur URLs auflisten, die Sie wirklich indexiert haben möchten und die ein Crawler erfolgreich laden kann.
Schließen Sie Seiten ein, die:
- Indexierbar sind (nicht durch robots blockiert, nicht mit
noindexmarkiert) - Kanonisch zu sich selbst sind (oder Sie sicher sind, dass die gelistete URL die kanonische ist)
- 200 zurückgeben und echten Inhalt rendern
Halten Sie fern: facettierte Filter, interne Suchergebnisse, endlose Parameter-URLs, Duplikate und dünne Seiten, die Sie nicht ranken sehen wollen. Wenn eine URL für Nutzer eine Sackgasse ist, ist sie meist auch eine Sackgasse fürs Crawling.
Wie oft aktualisieren bei häufiger Veröffentlichung
Wenn Sie täglich oder stündlich veröffentlichen, behandeln Sie Ihre Sitemap wie einen lebendigen Feed. Aktualisieren Sie sie, sobald neue Seiten live gehen, und entfernen Sie URLs, die weg sind oder nicht mehr indexierbar. Eine Woche zu warten kann dazu führen, dass Suchmaschinen alte Bestände crawlen, während sie Ihre neuesten Seiten verpassen.
Verwenden Sie das Feld lastmod nur, wenn Sie es ehrlich setzen können. Es sollte bedeutende Inhaltsänderungen widerspiegeln, nicht jeden kleinen Edit oder Re-Save. Aufgeblähte lastmod-Daten lehren Crawler, ihm nicht mehr zu vertrauen.
Große Sites: mehrere Sitemaps und ein Sitemap-Index
Wenn Ihre Site wächst, teilen Sie Sitemaps nach Typ (Blogposts, Glossar, News) oder nach Zeit (monatlich). Kleinere Sitemaps aktualisieren sich schneller, und Probleme sind leichter zu erkennen.
Ein Sitemap-Index fungiert als Verzeichnis, das auf jede Sitemap-Datei zeigt. Er hilft auch, Besitzverantwortung aufzuteilen, sodass eine Person die Blog-Sitemap pflegt und eine andere Produkt- oder Glossar-URLs verwaltet.
Sitemap-Hygiene-Checks, die Probleme früh erkennen
Führen Sie diese Checks regelmäßig durch, besonders nach großen Releases:
- URLs geben 200 zurück (nicht 3xx, 4xx oder 5xx)
- Gelistete URLs stimmen mit der kanonischen URL der Seite überein
- Noindex-Seiten sind nicht enthalten
lastmodändert sich nur bei echten Inhaltsänderungen- Die Sitemap wächst nicht mit Duplikaten oder Parameter-URLs
Wenn Sie Seiten via API oder CMS generieren, automatisieren Sie diese Checks, damit Fehler nicht mit Ihnen skalieren.
Canonical-, noindex- und robots-Checks vor dem Veröffentlichen
Bei hohem Volumen vervielfachen sich kleine technische Fehler schnell. Eine falsche Einstellung in einem Template kann hunderte Seiten vor Suchmaschinen verbergen oder Crawler mit Duplikaten überfluten.
Wählen Sie eine bevorzugte URL-Version
Suchmaschinen möchten eine Hauptversion jeder Seite. Entscheiden Sie sich für ein bevorzugtes Format und halten Sie es überall ein: HTTPS vs. HTTP, www vs. non-www und mit oder ohne abschließenden Slash.
Wenn Ihre Site über mehrere Wege erreichbar ist (z. B. mit und ohne Slash), erzeugen Sie Kopien, die gleich gelesen werden. Das macht Discovery langsamer und Indexierung weniger vorhersehbar.
Canonical- und Indexierungssteuerungen: was zu prüfen ist
Canonical-Tags sagen Suchmaschinen: "Diese Seite ist eine Kopie, indexiert bitte die andere." Sie helfen bei Near-Duplicates (Druckseiten, gefilterte Ansichten, sehr ähnliche Standortseiten), können aber gefährlich werden, wenn sie breit angewendet werden.
Ein häufiges Fehlerbild: Ein neues Blog-Template wird ausgerollt und setzt versehentlich das Canonical für jeden Beitrag auf die Blog-Startseite. Crawler holen weiterhin die Seiten, aber die Indexierung stockt, weil jede Seite behauptet, nicht die Hauptversion zu sein.
Bevor Sie eine Charge veröffentlichen, prüfen Sie stichprobenartig einige neue URLs:
- Das Canonical zeigt auf sich selbst bei normalen Seiten (nicht auf eine Kategorie- oder Startseite).
- Die Seite ist indexierbar (kein meta
noindexund keinX-Robots-Tag: noindex). - robots.txt erlaubt das Crawlen der Pfade, die neue Seiten nutzen.
- Redirects landen in einem Schritt (vermeiden Sie Ketten).
- Die finale URL entspricht Ihrer bevorzugten Version (gleicher Host, Protokoll und Slash-Stil).
Beachten Sie auch "Noise"-Seiten. Tag-, Kategorie- und paginierte Seiten können für Nutzer nützlich sein, aber sie erzeugen endlose URLs mit geringem Wert, wenn Ihr System viele Kombinationen erzeugt. Dieser Lärm konkurriert mit neuen Inhalten um Aufmerksamkeit.
Eine praktische Regel: Halten Sie wichtige Hub-Seiten crawlbar, verhindern Sie aber, dass dünne oder repetitive Varianten sich vervielfältigen.
Schritt-für-Schritt: ein skalierbarer Publish- und Indexierungs-Workflow
Make pages worth indexing
Tighten structure, clarity, and intent match so crawlers see each page as worth indexing.
Behandeln Sie jede Charge wie ein kleines Release. Das Ziel ist, Seiten zu liefern, die leicht zu crawlen, leicht zu verstehen und sofort mit dem Rest Ihrer Site verbunden sind.
1) Charge vorbereiten (bevor Sie auf "Veröffentlichen" drücken)
Führen Sie schnelle Checks an Templates und Inhalten durch, damit Sie nicht 200 neue Probleme auf einmal kreieren:
- Bestätigen Sie, dass jede Seite 200 OK zurückgibt (keine versehentlichen 404s, Redirects oder blockierte Renderings).
- Prüfen Sie, dass Titel, Meta-Description und eine eindeutige primäre Überschrift (H1) vorhanden sind und sich nicht in der Charge wiederholen.
- Verifizieren Sie, dass Canonical-Tags zur richtigen bevorzugten URL zeigen.
- Fügen Sie nur dann strukturierte Daten hinzu, wenn sie korrekt sind (z. B. Article für Blogposts).
- Stellen Sie sicher, dass Seiten indexierbar sind (kein
noindex, robots-Regeln erlauben Crawling).
Wenn möglich, staffeln Sie Releases. 50 Seiten pro Tag an 4 Tagen zu veröffentlichen ist leichter zu überwachen als 200 in einer Stunde, und es hilft, Template-Fehler früh zu entdecken.
2) Veröffentlichen und Seiten schnell discoverable machen (innerhalb von Minuten)
Veröffentlichen ist nicht das Zielende. Neue URLs brauchen klare Wege von bekannten Seiten.
Nach dem Livegehen konzentrieren Sie sich auf drei Aktionen: interne Links von relevanten Hub-Seiten hinzufügen, Ihre XML-Sitemap aktualisieren und einen verantwortungsbewussten Indexing-Ping senden (z. B. IndexNow) nur für die neuen URLs.
3) In den ersten 48 Stunden überwachen (und was zu tun ist, wenn nichts passiert)
Geben Sie Suchmaschinen Zeit, aber warten Sie nicht blind. Prüfen Sie in den ersten ein bis zwei Tagen eine Stichprobe von 10 URLs und vergewissern Sie sich, dass sie erreichbar, intern verlinkt und in der Sitemap enthalten sind.
Wenn sie nach 48 Stunden noch nicht auftauchen, priorisieren Sie Lösungen, die Discovery freischalten:
- Fügen Sie stärkere interne Links hinzu (von stark frequentierten Seiten, Kategorie-Seiten und aktuellen Beiträgen).
- Entfernen Sie Crawl-Fallen (endlose Filter, Kalenderseiten, duplizierte Tag-Seiten).
- Prüfen Sie Canonicals und
noindexerneut (eine falsche Einstellung kann eine gesamte Vorlage verbergen). - Bestätigen Sie, dass die Sitemap die neuen URLs enthält und
lastmodkorrekt ist. - Senden Sie einen Indexing-Ping nur für URLs, die Sie geändert oder neu hinzugefügt haben.
Beispiel: Wenn Sie 120 Glossarseiten veröffentlichen, veröffentlichen (oder aktualisieren) Sie auch 3–5 Hub-Seiten, die auf sie verlinken. Hubs werden oft zuerst gecrawlt und ziehen neue Seiten mit.
Proaktive Indexing-Pings (inklusive IndexNow) verantwortungsvoll einsetzen
Indexing-Pings sind ein nützlicher Anschub, kein magischer Schalter. Sie helfen besonders, wenn Sie viele Seiten veröffentlichen und Suchmaschinen Änderungen schnell merken sollen, vor allem bei zeitkritischen Updates (Preisänderungen, ausverkauft, Eilmeldungen) oder wenn Sie URLs entfernen und wollen, dass sie schneller fallen.
Sie helfen nicht, wenn die Seite durch robots.txt blockiert ist, auf noindex steht, keine internen Links hat oder Fehler zurückgibt. In diesen Fällen schicken Pings nur Bots zu einer Sackgasse.
Was IndexNow macht (einfach erklärt)
IndexNow ist eine einfache "diese URL hat sich geändert"-Meldung, die Sie an teilnehmende Suchmaschinen senden. Anstatt darauf zu warten, dass Crawler Änderungen selbst entdecken, liefern Sie eine Liste von URLs, die neu, aktualisiert oder entfernt wurden. Suchmaschinen können diese URLs dann früher crawlen. Die Indexierung bleibt ihre Entscheidung, aber die Discovery wird oft schneller.
Beispiel: Sie aktualisieren 200 ältere Beiträge mit neuen Abschnitten. Ohne Pings könnten Crawler Tage oder Wochen brauchen, um alle erneut zu besuchen. Mit IndexNow können Sie sie direkt auf die geänderten URLs hinweisen.
Halten Sie Ping-Batches an echten Änderungen orientiert:
- Neu veröffentlichte URLs, die 200 zurückgeben und intern verlinkt sind
- Aktualisierte URLs, bei denen sich der Inhalt substanziell geändert hat
- Entfernte URLs (404/410) oder weitergeleitete URLs (301) nachdem die Änderung live ist
- Nur kanonische URLs (vermeiden Sie Varianten, Parameter oder Tracking-URLs)
Rauschen macht Pings nutzlos. Vermeiden Sie mehrfache Pings derselben URL pro Stunde, das Senden von URLs bevor sie erreichbar sind oder das Versenden riesiger Listen, wenn nur wenige Seiten sich geändert haben.
Häufige Fehler, die bei großem Umfang Indexierungsverzögerungen verursachen
Update content without delays
Keep fast-changing pages fresh and notify search engines when content meaningfully changes.
Indexierungsverzögerungen sind oft kein Problem der Suchmaschine. Meist sind sie selbstverschuldet. Das Ziel ist einfach: Machen Sie es Crawlern leicht, Ihre besten URLs zu finden, und schwer, Zeit mit allem anderen zu verschwenden.
Eine Falle ist die Massenproduktion von Seiten, die Ihnen unterschiedlich erscheinen, für Crawler aber gleich sind. Wenn Hunderte Seiten nur einen Stadtnamen, ein Produkt-Adjektiv oder ein paar Sätze austauschen, können sie als Near-Duplicates behandelt werden. Crawler verlangsamen sich, indexieren weniger Seiten oder wählen eine andere Version als die gewünschte.
Ein weiterer Crawl-Budget-Killer ist unkontrolliertes URL-Wachstum. Facettierte Filter, interne Suche, Tag-Seiten, Kalenderarchive und Tracking-Parameter können sich zu Tausenden crawlbarer URLs vervielfältigen. Selbst wenn sie harmlos sind, konkurrieren sie mit neuen Inhalten um Aufmerksamkeit.
Fehler, die am häufigsten auftreten:
- Große Chargen sehr ähnlicher Seiten veröffentlichen, ohne einzigartigen Wert.
- Tags, Filter, interne Suche und Parameter unbegrenzt URLs erzeugen lassen.
- Sich allein auf die Sitemap verlassen, ohne starke interne Links von relevanten Hubs.
- Redirectende, nicht-kanonische, blockierte oder
noindex-URLs in Sitemaps einschließen. - URLs direkt nach dem Start umbenennen oder verschieben, was Re-Crawls, Redirects und Duplikat-Signale erzeugt.
Beispiel: Ein Immobilien-Blog veröffentlicht in einer Woche 500 Nachbarschafts-Guides. Wenn jeder Guide hauptsächlich ein Template mit ausgetauschten Phrasen ist und die Site zudem unbegrenzt Filterkombinationen (Schlafzimmer, Bäder, Preis, Sortierung) offenlegt, können Crawler in den Filtern feststecken, während die Guides unentdeckt bleiben.
Die Lösung besteht meist weniger im Mehr-tun und mehr im Signale-Verschärfen: Verlinken Sie neue Seiten von einigen gut besuchten Kategorie-Seiten, halten Sie Sitemaps sauber und frieren Sie URLs ein, bis Seiten gecrawlt und stabil sind.
Eine schnelle Checkliste und nächste Schritte
Kleine Probleme summieren sich schnell bei hohem Volumen. Diese Checks helfen, neue URLs nicht stecken zu lassen.
Schnelle Publish-Checkliste (pro Seite)
- Erreichbar und schnell: gibt 200 zurück, keine Redirect-Ketten, keine Serverfehler.
- Indexierbar: kein versehentliches
noindex, keine blockierenden robots-Regeln, nicht hinter Login. - Sauberes Canonical: zeigt auf die korrekte finale URL (nicht Staging, nicht eine Parameter-URL).
- Discoverable: mindestens ein relevanter interner Link von einer indexierten Seite.
- In der Sitemap: erscheint in der richtigen XML-Sitemap, mit korrektem
lastmodund ohne Duplikate.
Wenn eines davon fehlschlägt, beheben Sie es, bevor Sie weiter veröffentlichen. Sonst bauen Sie einen Rückstau auf, bei dem Crawler immer wieder die falschen URLs besuchen.
Eine einfache wöchentliche Routine (15–30 Minuten)
Nehmen Sie sich einen Tag pro Woche für leichte Aufräumarbeiten:
- Prüfen Sie einige neue URLs stichprobenartig und bestätigen Sie, dass sie gecrawlt und indexiert werden.
- Entfernen Sie redirectende, kanonisierte,
noindex- und fehlerhafte URLs aus Sitemaps. - Achten Sie auf Spitzen bei 5xx-Fehlern, langsamen Antwortzeiten und wachsender Redirect-Anzahl.
- Kürzen Sie dünne Tag-Seiten, Duplikate und Parameter-Seiten, die kein Crawling verdienen.
Wenn Ihr Team URLs in Tabellen kopiert, Sitemaps manuell bearbeitet und Indexierungsanfragen von Hand sendet, ist Automatisierung oft der Wendepunkt. Einige Teams verwenden ein System wie GENERATED (generated.app), um Inhalte zu erzeugen und zu polieren, Sitemaps aktuell zu halten und IndexNow-Pings als Teil eines API-gesteuerten Publish-Workflows zu senden, damit der Prozess konsistent bleibt, wenn die Ausgaben wachsen.
Häufige Fragen
What does “Crawled, currently not indexed” actually mean?
It usually means the bot fetched the page, but decided not to store it as a searchable result. The fastest wins are to confirm the page is truly unique, clearly matches a real search intent, and isn’t sending mixed signals like a wrong canonical or an accidental noindex.
How is “Discovered, currently not indexed” different from “Crawled, currently not indexed”?
“Discovered” means the search engine knows the URL exists, but hasn’t fetched it yet. This is often a discovery problem: add strong internal links from already-crawled pages, make sure the URL is in an up-to-date XML sitemap, and remove crawl traps that distract bots from your new URLs.
How do I quickly tell if I have a discovery problem or a quality problem?
Start with a small sample, like 20 new URLs. Check discovery first (indexable, returns 200, in the sitemap, and linked internally), then check “worth indexing” (not a near-duplicate, actually answers a question, and has enough substance). The pattern in that sample usually tells you which side is broken.
What is crawl budget, and why does it matter when I publish a lot?
Crawl budget is the limited attention bots give your site, especially when you publish a lot. If you generate endless low-value URLs (parameters, filters, duplicates), crawlers waste visits and your important pages wait longer to be crawled and evaluated.
Why do internal links affect indexing speed so much?
Because bots follow links, and they revisit popular, well-linked pages more often. If your new pages aren’t linked from pages that already get crawled, they can sit unnoticed even if your sitemap is perfect.
What’s a simple “new content hub,” and how does it help?
A “new content” hub page is a single page that’s easy to reach from your main navigation and always shows recent URLs. It helps crawlers repeatedly find fresh links without hunting, as long as it stays tidy and doesn’t turn into an endless scrolling page.
What should (and shouldn’t) go into my XML sitemap at scale?
Only include URLs you actually want indexed and that return a clean 200 with real content. If your sitemap is full of redirecting, parameterized, canonicalized, or noindex URLs, you’re telling crawlers to spend time on pages you don’t even want.
How should I use the sitemap `lastmod` field without hurting trust?
Use lastmod only for meaningful content changes, not every small edit or re-save. If you inflate lastmod, crawlers learn to ignore it, and you lose one of the easiest signals for what’s actually new or updated.
What canonical tag mistakes cause big indexing delays?
A bad canonical can quietly block indexing at scale, like pointing every post to the blog homepage. Before publishing a batch, spot-check a few pages to confirm the canonical points to the page itself (for normal pages) and matches your preferred URL format.
When should I use IndexNow (or other indexing pings), and when is it pointless?
IndexNow is best used as a nudge for URLs that are genuinely new, meaningfully updated, or removed, and only after they’re accessible and internally linked. It won’t fix pages that are blocked, noindex, broken, or thin; it just sends crawlers to the same dead end faster.