Auf einer mehrsprachigen Seite ist „Duplicate Content“ selten eine exakte Kopie. Meist sind es Nahe-Kopien: dasselbe Template, dieselben Produktspezifikationen, dieselben Überschriften, nur kleine Abschnitte sind anders. Manchmal ist es noch einfacher: der englische Originaltext landet auf mehreren Sprachseiten, weil die Übersetzung unvollständig ist, sich verzögert oder stillschweigend ausfällt. Dort beginnen die Probleme mit mehrsprachigem Duplicate Content.
Suchmaschinen können auch die falsche Sprache anzeigen, weil sie raten müssen. Wenn deine Sprachversionen sich zu ähnlich sehen, keine klaren Sprachsignale haben oder sich gegenseitig chaotisch referenzieren, wählt Google möglicherweise die falsche Version als Hauptseite. Nutzer landen auf einer Seite, die sie nicht lesen können, springen ab, und die richtige Sprachseite bleibt unsichtbar, obwohl sie existiert.
Index-Bloat ist das andere häufige Problem. Er entsteht, wenn deine Seite viele wenig wertvolle URLs erzeugt, die dennoch gecrawlt und indexiert werden. Typische Ursachen sind dünn belegte automatisch erzeugte Seiten (z. B. leere Tag-Seiten oder interne Suchergebnisse), nahe Duplikate über Sprachen hinweg, endlose Varianten durch Sortierung und Filter sowie Staging- oder Testübersetzungen, die versehentlich öffentlich bleiben.
Du könntest bereits betroffen sein, wenn du Muster siehst wie: eine Sprache bekommt Impressionen, eine andere erscheint nie; Seiten ranken im falschen Land oder in falscher Sprache; Crawl-Reports füllen sich mit „discovered“ oder „crawled“-Seiten, die nicht indexiert werden; oder Suchergebnisse zeigen merkwürdige Varianten (Parameter, veraltete Seiten, Duplikate).
Ein nützliches Denkmodell: Suchmaschinen wollen eine klare beste Seite pro Intent und pro Sprache. Bietet deine Seite zu viele ähnliche Optionen, wählt Google für dich — und nicht immer die, die du wolltest.
Bevor du an URL-Strukturen oder hreflang herumstellst, entscheide, wofür du in jedem Markt eigentlich ranken möchtest. Viele mehrsprachige Duplicate-Content-Probleme beginnen hier: Seiten werden ohne klaren Grund mehrfach veröffentlicht.
Eine praktische Regel: Eine Seite pro Sprache, wenn sich die Nutzererfahrung mit der Sprache ändert. Eine einzelne Seite, die nachträglich die Sprache wechselt, kann bei kleinen Sites funktionieren, verwirrt aber Suchmaschinen und Nutzer oft, wenn Titel, Text und interne Links nach dem Laden wechseln. Separate, crawlbare Seiten sind einfacher zu messen, einfacher zu prüfen und später leichter mit hreflang zu verbinden.
Nicht alles muss übersetzt werden. Übersetze das, was Konversionen antreibt oder lokale Intentionen beantwortet (Produktseiten, Preise, wichtige Hilfeseiten). Lass Inhalte in einer Sprache, wenn Übersetzung nur Rauschen oder Risiko bringt — z. B. juristische Texte, die du nicht lokalisieren kannst, oder technische Ressourcen, die nur dein englischsprachiges Publikum nutzt.
Ähnliche Seiten können valide sein, wenn sie klar nach Publikum getrennt sind. Eine englische US- und eine englische UK-Seite können den Großteil des Textes teilen, sich aber in Rechtschreibung, Währung, Versandinformationen und Beispielen unterscheiden. Das ist keine schädliche Duplikation, sofern jede Seite eine eigene Zielgruppe bedient und als eigenständige Version behandelt wird.
Setze realistische Ziele pro Locale, bevor du skalierst. Entscheide, welche Länder und Sprachen du wirklich supporten kannst, welche Seiten zuerst lokalisiert werden müssen, wie Erfolg pro Locale aussieht (Traffic, Trials, Leads, Verkäufe), welche Übersetzungsqualität du akzeptierst und wann die nächste Locale hinzukommt.
Beispiel: Eine SaaS-Seite launcht Spanisch und Deutsch. Spanisch fokussiert auf Wachstum (mehr Trials), Deutsch richtet sich an Enterprise (weniger Traffic, höhere Conversion). Das ändert, was du zuerst übersetzt und wie streng dein Review-Prozess sein muss.
Wenn du eine Content-Plattform wie GENERATED nutzt, bleibt dieser Targeting-Schritt wichtig. Content-Generierung beschleunigt zwar, ersetzt aber nicht die Entscheidung, für wen jede Seite gedacht ist und wie du Ergebnisse misst.
Deine URL-Struktur ist die erste Leitplanke gegen mehrsprachige Duplikate. Ein klares, konsistentes Muster hilft Suchmaschinen zu verstehen, dass jede Sprachversion für andere Leser gedacht ist — und keine konkurrierende Kopie.
Sprachordner auf einer Domain sind meist die einfachste Wahl. Alles lebt unter derselben Seite, Analytics bleiben zentral, und internes Linking ist leichter konsistent zu halten. Das funktioniert gut für kleine bis mittelgroße Sites und globale Marken.
Sprach-Subdomains können funktionieren, schaffen aber oft operative Trennung. Teams behandeln Subdomains manchmal wie eigene Sites, was zu ungleichmäßiger Navigation, fehlenden Seiten und unbeabsichtigter Duplizierung führt.
Länderspezifische Domains sind am stärksten, wenn du tatsächlich wie separate Geschäfte pro Land operierst — mit anderer Preisgestaltung, rechtlichen Seiten oder Support. Der Nachteil ist der Mehraufwand: mehr Domains zu verwalten, mehr Tracking-Setup und mehr Möglichkeiten, dass Inhalte auseinanderdriften.
Wenn du eine einfache Default-Empfehlung willst: Sprachordner sind meist am einfachsten sauber zu halten; Subdomains sind sinnvoll, wenn die Infrastruktur Trennung erzwingt; Länderdomains machen nur Sinn, wenn echte länderspezifische Operationen existieren (nicht nur kosmetisch).
Nutze nur Sprache, wenn der Inhalt für alle Sprecher dieser Sprache im Wesentlichen gleich ist. Nutze Sprache plus Land nur, wenn sich die Bedeutung merklich ändert — z. B. Währung, Rechtschreibung, Versandregeln, Compliance-Text oder Produktverfügbarkeit.
Ein häufiger Fehler ist, Patterns im Laufe der Zeit zu mischen (z. B. ein Strukturmuster für Blogposts und ein anderes für Produktseiten). Wähle einen Ansatz und bleibe dabei. Wenn ein Wechsel nötig ist, plane Redirects sorgfältig und stelle sicher, dass nur eine Version jeder Seite ranken soll.
Wenn du Content per API bereitstellst (einschließlich Systemen wie GENERATED auf generated.app), halte Locale in einem Single-Source-of-Truth-Feld und generiere URLs daraus. Das verhindert „fast identische“ Duplikate, die durch mehrere Zugriffswege auf denselben Inhalt entstehen.
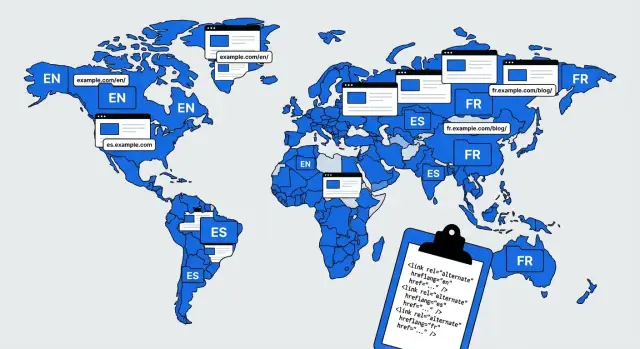
Hreflang ist ein Hinweis, der Suchmaschinen sagt: „Diese Seiten sind dieselbe Idee, nur in verschiedenen Sprachen (oder Ländern).“ Richtig eingerichtet reduziert es die Wahrscheinlichkeit, dass deine französische Seite für englische Suchanfragen erscheint oder dass eine englische Variante an falscher Stelle outrankt.
Hreflang-Werte folgen einem einfachen Muster: zuerst Sprache, dann optional Region.
Verwende eine Region nur, wenn die Seite wirklich gezielt ist (Währung, Rechtschreibung, Versand, rechtliche Anforderungen). Wenn du eine englische Seite für alle Nutzer hast, ist language-only oft sauberer, als jede mögliche Region abzudecken.
Zwei Regeln vermeiden die meisten falschen Sprachprobleme.
Erstens: Jede Seite sollte einen self-referencing hreflang-Eintrag enthalten. Die englische Seite sollte sich also als englisch deklarieren, nicht nur die anderen Sprachen auflisten. Das hilft Suchmaschinen, die Gruppe zu bestätigen.
Zweitens: Alternativen müssen in der ganzen Gruppe konsistent sein. Wenn Seite A Seiten B und C als Alternativen listet, sollten B und C zurück auf A und aufeinander zeigen. Fehlt eine Seite, kann die hreflang-Gruppe ignoriert werden und Seiten fangen an zu konkurrieren.
Nutze x-default nur für eine echte Catch-All-Seite, wie einen Sprachwahlschalter oder eine globale Startseite, die Nutzer wählen lässt. Verwende es nicht als Flickwerk für fehlende Sprachseiten.
Du kannst hreflang in der HTML-Seite, in der XML-Sitemap oder in HTTP-Headern veröffentlichen (letzteres meist für non-HTML-Dateien). Die meisten Sites wählen eine Methode und bleiben dabei. Methoden zu mischen schafft oft Inkonsistenzen — und Inkonsistenzen sind die Ursache falscher Sprachrankings.
Hreflang wird einfacher, wenn du es wie ein Mapping-Problem behandelst: Jede indexierbare Seite sollte ihre Äquivalente in anderen Sprachen deklarieren. Das Ziel ist, falsche Sprachrankings zu stoppen und Raten zu vermeiden.
Beginne mit einer Tabelle, die jedes indexierbare Seitenkonzept (z. B. „Preise“) und seine Locale-Versionen auflistet. Nimm nur Seiten auf, die du wirklich indexiert haben willst. Existiert eine Sprachversion nicht, lass die Zelle leer, anstatt auf ein Nahe-Duplikat zu verweisen.
Verfolge Basisdaten: Seitenname und Typ, URL pro Locale, Indexierbarkeit, letztes Änderungsdatum, die beabsichtigte Canonical und Hinweise zu Unterschieden (z. B. unvollständige Übersetzung oder locale-spezifischer Rechtstext).
Für jede Locale-Seite ist die sicherste Default-Einstellung eine self-referencing Canonical (die Canonical zeigt auf dieselbe Seite). Cross-Language-Canonicals sind eine häufige Ursache für mehrsprachige Duplicate-Probleme, weil sie Suchmaschinen sagen: „diese Übersetzung ist nicht die Hauptversion.“
Nachdem Canonicals gesetzt sind, füge hreflang-Annotationen hinzu, sodass jede Seite auf alle Alternativen verweist und sich selbst einschließt.
Hreflang muss reziprok sein: Wenn Englisch auf Spanisch zeigt, muss Spanisch zurück auf Englisch zeigen — und beide Seiten müssen indexierbar sein.
Vor dem Rollout stichprobenartig prüfen:
Wenn du Inhalte durch eine API generierst, erzeuge hreflang aus derselben URL-Map, die du fürs Routing nutzt. So bleibt alles konsistent, wenn neue Seiten live gehen.
Mehrsprachige Duplicate-Probleme entstehen oft durch kleine technische Entscheidungen, nicht durch schlechte Übersetzungen. Behebe die Grundlagen, reduziere Index-Bloat und mach es Suchmaschinen leichter, die richtige Sprache zu zeigen.
Nutze hreflang, um Sprache und Land zu erklären. Nutze Canonical-Tags, um die Haupt-URL zu wählen, wenn mehrere URLs denselben Inhalt zeigen.
Wichtig: Übersetzte Seiten sind in der Regel keine Duplikate, sondern Alternativen. Sie brauchen meist hreflang, nicht eine cross-language-Canonicalisierung.
Ein sicherer Default:
Tracking- und UI-Parameter sind klassische Quellen unbeabsichtigter Duplikate. Ein Crawler kann Parameter-Varianten als eigene Seiten ansehen, wenn du das zulässt.
Beherrsche das Problem, indem du Canonicals auf die saubere URL setzen lässt, interne Links ohne Tracking-Parameter pflegst, offensichtliche Tracking-Versionen bei Bedarf umleitest und noindex für Seiten nutzt, die existieren müssen, aber nicht in der Suche erscheinen sollen.
Filter und Sortierung können in near-infinite URL-Varianten explodieren, und das Problem multipliziert sich über Sprachen.
Wenn eine gefilterte Ansicht für die Suche nicht wertvoll ist, halte sie aus dem Index und canonicalize sie auf die Hauptkategorie. Wenn eine spezifische Filterseite wertvoll ist, behandle sie wie eine echte Landingpage: stabile URL, indexierbar, einzigartiger Text und korrekter hreflang.
Wenn du mehrsprachige Seiten per Templates lieferst (inkl. API-gesteuerte Setups wie GENERATED), implementiere diese Regeln einmal auf Template-Ebene. Ansonsten wiederholt sich derselbe Indexierungsfehler in jedem Locale.
Index-Bloat entsteht, wenn Suchmaschinen zu viele gleichartige Seiten oder Seiten finden, die nie öffentlich sein sollten. Das Ergebnis sind verschwendete Crawl-Ressourcen, verwässerte Signale und manchmal die falsche Sprachseite in der Suche.
Ein häufiger Schuldiger ist eine Sprachwahl-Seite, die versehentlich indexierbar ist. Wird sie siteweit verlinkt (z. B. im Header) und hat dünnen Inhalt, kann sie trotzdem für Crawler wichtig aussehen.
Ein weiteres großes Problem ist Auto-Übersetzung, die nur wenige Wörter ändert, während Template, Überschriften und der Großteil des Texts gleich bleiben. Du erhältst Nahe-Duplikate über Sprachen hinweg, die Relevanz verwässern und Duplicate-Filter auslösen können.
Hreflang-Fehler verstärken das Chaos. Fehlende Rückverweise zerstören die Gruppe, inkonsistente Codes verwirren das Targeting, und das Blockieren übersetzter Seiten, während sie trotzdem in hreflang referenziert werden, erzeugt Widersprüche, die sich als instabiles Indexing zeigen.
Für ein schnelles Audit prüfe zuerst: Sind Sprachwahlschalter indexierbar? Sind Übersetzungen dünn oder teilwiese? Ist hreflang reziprok über alle Sprachen? Sind Codes überall konsistent? Widersprechen Robots-Regeln oder noindex hreflang-Referenzen?
Auch eine saubere Übersetzung kann Ranking-Probleme verursachen, wenn wichtige SEO-Elemente in der Default-Sprache bleiben oder interne Links Nutzer in die falsche Locale schicken. Genau dort beginnen oft mehrsprachige Duplicate-Content-Probleme: Suchmaschinen sehen nahe identische Seiten mit gemischten Signalen.
Beginne mit einer Regel: Alle übersetzen aus derselben Source-Version. Ändert sich die Quelle kürzlich und ein Locale-Team arbeitet mit einem älteren Export, entstehen inkonsistente Abschnitte, veraltete Aussagen und brüchige interne Links.
Vor der Veröffentlichung und nochmal nach Live-Schaltung:
Ein schneller „Snippet-Scan“ hilft auch: Schau, was in der Suche erscheinen würde (Titel, Description, erste Überschrift). Wenn diese sauber sind, vermeidest du viele frühe Überraschungen.
Eine SaaS-Seite launcht spanische Seiten und übersetzt den Body gut, aber der Pricing-Link im spanischen Header führt zur englischen Pricing-Seite. Jetzt geben spanische Seiten intern Authority an englische URLs ab — und Nutzer springen ab. Die Korrektur von Header- und Footer-Links verbessert oft sowohl Rankings als auch Conversion.
Wenn du übersetzte Drafts automatisch erzeugst, füge vor der Indexierung eine finale menschliche Stichprobe hinzu. Das ist der schnellste Weg, Probleme zu entdecken, die Tools übersehen.
Stell dir ein kleines SaaS-Team mit einer Produktseite „Team Calendar“ vor, angeboten in Englisch, Spanisch und Französisch. Ziel: Jede Sprachseite soll in ihrer Sprache ranken, ohne als Duplikat einsortiert zu werden.
Sie beginnen mit einer Seiten-Map und gleichen Signale über alle drei Versionen ab:
Vor der Korrektur setzten sie auf Sprachwechsel per Query-Parameter. Verschiedene Varianten wurden indexiert, weil Nutzer unterschiedliche Versionen teilten und Tracking-Parameter sich anhäuften. Schlimmer: Spanisch und Französisch zeigten Canonicals auf die englische Seite, also behandelte Google Englisch als Hauptversion und die anderen Sprachen konnten nicht ranken.
Nach dem Wechsel zu einer sauberen, konsistenten Sprachstruktur leiteten sie die alten parameter-basierten URLs auf die richtigen Sprachseiten um, entfernten unnötige indexierbare Varianten und brachten Canonicals und hreflang in Einklang. Innerhalb weniger Wochen nahm der Crawl-Lärm ab und die Rankings stabilisierten sich.
Um Regressionen zu vermeiden, etablierten sie einen einfachen Workflow: Übersetzer prüfen Bedeutung und lokale Begriffe, ein SEO-Verantwortlicher checkt Titel und interne Links, ein Developer prüft Templates auf korrekte Canonical- und hreflang-Ausgaben, und ein QA-Editor verifiziert die Seite im Browser.
Bevor du eine neue Sprache hinzufügst, prüfe eine kleine Seitenstichprobe (Startseite, Kategorieseite, einen Top-Blogpost, eine Produktseite und eine Support-Seite). Viele Probleme starten klein und multiplizieren sich über Templates.
Stelle sicher, dass jede Locale-Seite indexierbar ist und normalen Response liefert, Inhalt klar für das Publikum geschrieben ist (nicht nur Navigation ausgetauscht), Canonicals auf dieselbe Locale-Seite zeigen, hreflang vorhanden und reziprok mit korrekten Codes ist und der Sprachwechsler Nutzer auf die passende Seite bringt (nicht zur Locale-Startseite).
Danach wähle eine Kennzahl und beobachte sie zwei Wochen: Anzahl indexierter Seiten pro Locale. Steigt die Zahl schneller als dein wirklicher Content-Zuwachs, erzeugst du vermutlich Duplikate durch Parameter, gefilterte Seiten, interne Such-URLs oder übriggebliebene Testseiten.
Wenn du über ein paar Sprachen hinaus skalierst, zählt Konsistenz mehr als Raffinesse. Freeze ein URL-Pattern, füge ein Release-Gate für jedes Locale hinzu (Templates, Canonicals, hreflang, Sitemap, Verhalten des Sprachwechslers), behalte eine kleine QA-Stichprobe, die du nach Site-Änderungen erneut prüfst, und halte unvollständige Übersetzungen aus dem Index, bis sie wirklich nützlich sind.
Wenn du GENERATED nutzt, hilft es, Prompts und Glossarbegriffe über Locales hinweg zu standardisieren und dann dieselbe QA-Stichprobe laufen zu lassen, bevor du Indexierung erlaubst. Da GENERATED auch CTA-Generierung und Performance-Tracking unterstützt, ist es nützlich, um zu sehen, wann eine Übersetzung korrekt ist, aber auf dem Markt nicht überzeugt.
Es handelt sich meist um Near-Duplicates, nicht um wortwörtliche Kopien. Seiten teilen Template, Überschriften und Spezifikationen; nur kleine Teile unterscheiden sich, oder die Originalsprache wird versehentlich in mehreren Locales veröffentlicht, weil die Übersetzung unvollständig ist.
Suchmaschinen müssen raten, wenn Sprachsignale schwach oder inkonsistent sind. Wenn Seiten zu ähnlich aussehen, hreflang fehlt oder defekt ist, oder interne Links zwischen Locales springen, kann Google die falsche Sprachversion auswählen, obwohl die korrekte existiert.
Index-Bloat bedeutet, dass viele wenig wertvolle URLs gecrawlt und indexiert werden, wodurch Signale verwässert und Crawling-Ressourcen verschwendet werden. Häufige Ursachen sind Parameter, Filter, dünne automatisch erzeugte Seiten und Test-/Staging-Übersetzungen, die öffentlich bleiben.
Als Regel: Erstelle pro Sprache eine crawlbare URL, wenn sich Inhalt und Seitensignale mit der Sprache ändern. Eine einzelne Seite, die nachträglich die Sprache wechselt, verwirrt Nutzer und Suchmaschinen und ist schwerer zu messen und zu prüfen.
Sprachordner (z. B. /de/) sind meist am einfachsten sauber zu halten: alles ist auf einer Domain, Tracking und internes Linking bleiben konsistent. Subdomains funktionieren, neigen aber oft zu organisatorischem Auseinanderdriften. Länderdomains sind sinnvoll, wenn das Geschäft pro Land wirklich anders ist.
Verwende nur Sprache (z. B. en, de), wenn die Experience für alle Sprecher gleich ist. Füge ein Land/Region hinzu, wenn sich Inhalte merklich ändern (Währung, Rechtsangaben, Verfügbarkeit, Rechtskonformität).
Setze zuerst Canonicals. In den meisten Fällen sollte jede übersetzte Seite eine selbstverweisende Canonical haben. Cross-Language-Canonicals unterdrücken oft Nicht-Default-Sprachen, weil sie signalisieren, dass die Übersetzung nicht die Hauptversion ist.
Häufige Fehler sind ungültige Sprach-/Region-Codes, fehlende self-referencing hreflang-Einträge und fehlende Reziprozität. Wenn eine Version fehlt, geblockt oder noindexed ist, oder auf falsche URLs zeigt, ignorieren Suchmaschinen eventuell die hreflang-Gruppe.
Behandle Parameter als potenzielle Duplikate und mache die saubere URL zur Standardversion. Halte interne Links frei von Tracking-Parametern, lasse Canonicals auf parameterfreie URLs zeigen und verhindere, dass endlose Sortier-/Filterzustände indexierbar werden.
Prüfe zuerst, ob Titel, Meta-Description und Hauptüberschriften lokalisiert sind und zur Intention passen. Kontrolliere Header/Footer/Body-Links, ob sie in derselben Sprache bleiben. Halte Teilübersetzungen oder minderwertige Übersetzungen aus dem Index, bis sie wirklich nützlich sind; API-gesteuerte Workflows wie GENERATED helfen, Konsistenz sicherzustellen.