29. Nov. 2025·7 Min. Lesezeit
Content-Pipeline mit einer API: Schritt-für-Schritt-Architektur
Baue eine Content-Pipeline mit einer API von der Idee bis zur Veröffentlichung: Generierung, Prüfung, Freigabe, Planung und Monitoring – mit einer einfachen Architektur, die du anpassen kannst.
Welches Problem eine Content-Pipeline löst
Eine Content-Pipeline ist die Abfolge von Schritten, die eine Idee von „das sollten wir veröffentlichen“ bis zur Live-Seite bringt. Sie umfasst in der Regel das Erstellen von Entwürfen, das Bearbeiten, Metadaten, Bilder, Freigaben und das Veröffentlichen. Ist die Pipeline klar definiert, weiß jede:r, was als Nächstes passiert, und Arbeit verschwindet nicht in Chat-Threads.
Die meisten Teams verlieren nicht allein beim Schreiben Zeit. Sie verlieren Zeit bei den kleinen, sich wiederholenden Aufgaben darum herum: Text zwischen Tools kopieren, auf Feedback warten, Formatierung reparieren, Überschriftenlänge prüfen, Alt-Text hinzufügen, Bilder in den richtigen Größen hochladen und Beiträge planen. Dieselben Fehler wiederholen sich, weil der Prozess im Kopf der Menschen lebt.
Eine API-basierte Pipeline verwandelt diese wiederkehrenden Aufgaben in vorhersehbare Anfragen zwischen Systemen: deinem CMS, deinem Backend und Diensten, die Inhalte erzeugen oder validieren. Das heißt nicht, dass ohne Kontrolle veröffentlicht wird. Es bedeutet, dass die langweiligen Teile standardmäßig passieren (Entwurfserstellung, Formatierung, Vorschläge für Metadaten, Bildvarianten, Statusupdates), während Menschen steuern, was live geht.
Eine praktische Definition von „automatisch“ sieht so aus:
- Entwürfe können automatisch erzeugt und vorbereitet werden, das Veröffentlichen geschieht jedoch nur aus einem genehmigten Status.
- Regeln werden standardmäßig durchgesetzt (Pflichtfelder, SEO-Basics), Editoren können aber bei Bedarf überschreiben.
- Änderungen werden automatisch protokolliert, die finale Freigabe bleibt jedoch menschlich.
Dieser Ansatz rechnet sich, wenn ihr häufig veröffentlicht, Inhalte mehrfach verwendet oder konsistente Ergebnisse über verschiedene Autor:innen hinweg wollt. Wenn ihr selten veröffentlicht und der Prozess ohnehin einfach ist, kann manuell schneller sein.
Beispiel: Ein kleines Marketingteam schreibt Produkt-Updates in einem Headless-CMS. Eine Person erstellt den Entwurf, eine andere bearbeitet, eine dritte kümmert sich um Bilder und das Timing. Mit einem API-Workflow kann ein neuer Entwurf aus einer Vorlage erstellt, mit vorgeschlagenen Metadaten gefüllt und automatisch mit skalierten Bildvarianten kombiniert werden. Der Editor konzentriert sich dann auf Genauigkeit, Klarheit und Stimme.
Die grundlegenden Phasen und Rollen
Eine API-getriebene Pipeline funktioniert am besten, wenn alle dieselben wenigen Phasen nutzen. Du willst genug Struktur, um Chaos zu vermeiden, aber nicht so viel, dass Veröffentlichen zu Status-Meetings wird.
Die meisten Teams kommen auf fünf Phasen:
- Brief (was zu schreiben ist und warum)
- Entwurf (erste Version)
- Prüfung (Qualität, Brand- und Faktentest)
- Veröffentlichen (Planen und Live-Schalten)
- Messen (sehen, was funktionierte und was nicht)
Jede Phase sollte eine:n klare:n Verantwortliche:n haben und spezifische Daten für die nächste Phase liefern.
Wer macht was
Rollen können Jobtitel oder einfach Hüte sein, die Leute aufsetzen. Wichtig ist, dass pro Schritt eine Person rechenschaftspflichtig ist.
Eine einfache Aufteilung:
- Requester: definiert Thema, Zielgruppe, Ziel und Einschränkungen (Ton, Länge, Muss-Punkte).
- Editor: verbessert Klarheit und Struktur, prüft SEO-Basics, markiert fehlende Informationen.
- Approver: gibt die Freigabe für Genauigkeit, rechtliche, Marken- oder Produktangaben.
- Publisher: plant, fügt Metadaten hinzu und pusht die Seite live.
CMS vs. Backend-Service
In diesem Setup ist das CMS der Ort, an dem Inhalte leben und Menschen arbeiten: Entwürfe, Kommentare, Freigaben und Felder für die Veröffentlichung. Der Backend-Service ist die Automatisierungsschicht: Er ruft Generierungs-APIs auf, wendet Regeln an, speichert Logs und verschiebt Items durch Status.
Ein nützliches Modell: Das CMS ist die Source of Truth für den Artikel, das Backend der Verkehrskontrolleur.
Über die Phasen hinweg müssen ein paar Dinge zuverlässig mitwandern: der Brief, der Artikelsatz, SEO-Felder (Titel, Beschreibung, Keywords), Assets (Bild-Prompts und finale Bild-IDs), Ownership (wer zugewiesen ist) und Timestamps für Statusverfolgung.
Beispiel: Ein Requester legt ein kurzes Briefing im CMS an. Das Backend holt es ab, generiert einen Entwurf und vorgeschlagene Metadaten und gibt alles an das CMS zur Bearbeitung zurück. Nach der Freigabe plant der Publisher die Veröffentlichung. Später protokolliert das Backend die Performance, damit der nächste Brief spezifischer wird.
Definiere dein Content-Modell und Status
Automatisierung funktioniert am besten, wenn jedes Content-Stück ein vorhersehbares Objekt ist, nicht ein loses Dokument. Bevor du Generierung, Review und Publishing automatisierst, entscheide, welche Felder du speicherst und was an jedem Schritt als „fertig“ gilt.
Beginne mit einem Content-Objekt, das durch dein System reisen kann. Halte es einfach, aber so vollständig, dass ein Editor es ohne langes Suchen prüfen kann.
Ein praktisches Set an Feldern:
- Titel und Slug (oder URL-Key)
- Outline (Überschriften und Kernpunkte)
- Body (voller Artikelinhalt)
- Bilder (Prompts, Alt-Text, finale Bild-IDs)
- Metadaten (Beschreibung, Tags, Ziel-Keyword, canonical, Autor)
Status sind die andere Hälfte des Modells. Sie sollten in Alltagssprache sein, sich ausschließen und an Berechtigungen gekoppelt werden. Ein gängiges Set:
- Entwurf
- In Prüfung
- Genehmigt
- Geplant
- Veröffentlicht
Behandle den Status wie einen Vertrag zwischen Mensch und Automatisierung. Generierungstools können in Entwurf schreiben, aber nur ein Editor (oder eine definierte Freigaberegel) sollte auf Genehmigt setzen. Planung sollte ein publish_at-Zeitfeld speichern und Änderungen erlauben, bis der Beitrag live geht.
Revisionshistorie macht Automatisierung sicher. Speichere eine revisions-ID für jede wesentliche Änderung, zusammen mit wer sie gemacht hat und warum. Ein nützlicher Datensatz enthält: vorheriger Wert, neuer Wert, Editor-ID, Timestamp und eine optionale Notiz wie „behauptung korrigiert“ oder „Meta-Beschreibung aktualisiert“. Wenn du ein Generierungs-Tool wie GENERATED verwendest, speichere auch die generation request ID, um nachvollziehen zu können, welcher Prompt und welche Einstellungen den Text produziert haben.
Füge schließlich IDs und Timestamps überall hinzu. Jedes Content-Item braucht eine stabile content_id plus created_at, updated_at und published_at. So vermeidet ihr die Debatte „Welche Version haben wir freigegeben?“ und Auditierungen werden einfacher.
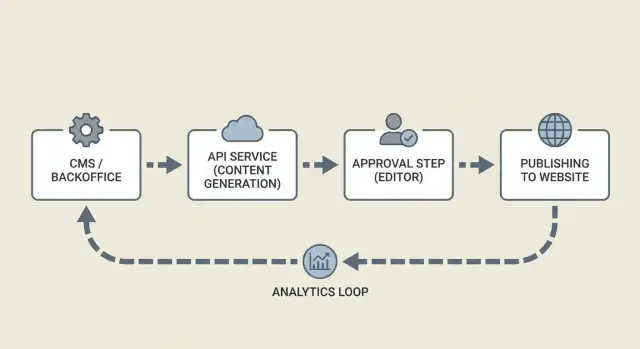
Architekturüberblick: Services und wie sie kommunizieren
Eine zuverlässige Pipeline teilt die Arbeit in kleine Services, die klare Nachrichten austauschen. Das hält dein CMS sauber, macht Fehler leichter wiederholbar und lässt Menschen sich auf Freigaben konzentrieren.
Auf hoher Ebene hast du meist vier Teile:
- Generator-Service: erhält ein Briefing und liefert einen Entwurf plus vorgeschlagenen Titel, Überschriften und Metadaten.
- Approval-UI: wo Editoren lesen, kommentieren, Änderungen anfordern und freigeben.
- Publisher-Worker: nimmt genehmigte Inhalte, aktualisiert das CMS und plant oder veröffentlicht.
- Tracking-Store: protokolliert, was passiert ist (Erfolg, Fehler, Timestamps) und erfasst später Performance-Signale.
Wie Services kommunizieren, ist wichtiger als welche Tools du nutzt. Webhooks oder eine Queue sind üblich, damit langsame Schritte (Generierung, Bild-Rendering, CMS-Publishing) die UI nicht blockieren. Der Generator sollte mit einer ID antworten, und jeder nachfolgende Schritt sollte sich auf dieselbe ID beziehen.
Ein einfacher Ablauf: Das Backend erstellt eine Content-Anfrage, der Generator liefert einen Entwurf, ein Editor genehmigt, und der Publisher bestätigt das CMS-Ergebnis. Zwischen jedem Schritt speichere einen Status, damit du nach einem Absturz sauber weitermachen kannst.
Welche Daten zwischen Services wandern
Halte Payloads klein und vorhersehbar. Zum Beispiel:
- Ein Brief (Inputs) plus ein Content-Modell (erforderliche Felder)
- Entwurfs-Inhalt plus Notizen der Editoren
- Eine Publish-Anweisung (sofort veröffentlichen vs. geplanter Zeitpunkt)
- Eine Publish-Receipt (CMS-Entry-ID, Slug, Warnungen)
Tracking und Feedback-Loops
Tracking ist mehr als Analytics. Es ist deine Audit-Spur.
Wenn das Veröffentlichen scheitert, weil ein erforderliches CMS-Feld fehlt, protokolliere den genauen Fehler und setze das Item auf „Braucht Fixes“. Wenn die Performance später niedrige Klicks zeigt, trigger ein gezieltes Überarbeitungs-Request (z. B. teste einen neuen Titel und eine neue Meta-Beschreibung).
Beispiel: Ein Marketingteam stellt 20 Produkt-FAQs in die Queue. Entwürfe werden über Nacht generiert, Editoren prüfen morgens, und der Publisher-Worker plant sie. Das Log zeigt 18 erfolgreiche und 2 fehlgeschlagene Fälle, weil eine Kategorie-Zuordnung fehlte; diese beiden werden zur schnellen Korrektur zurückgeleitet.
Schritt für Schritt: Baue die Pipeline Ende-zu-Ende
Auf mehr Sprachen skalieren
Skaliere mehrsprachige Workflows, ohne deine Pipeline für jede Locale neu aufzubauen.
Eine gute Pipeline dreht sich weniger ums Auto-Schreiben als darum, dass dasselbe Content-Stück sicher von der Idee bis zur Veröffentlichung wandert, mit klaren Übergaben und einer nachvollziehbaren Spur.
Starte mit einem wiederverwendbaren Brief
Bevor irgendetwas per API aufgerufen wird, erstelle eine Briefing-Vorlage. Halte sie kurz, damit Leute sie wirklich ausfüllen, aber strukturiert genug, dass der Generator nicht raten muss.
Ein solides Brief enthält meist:
- Thema und die eine Frage, die der Beitrag beantwortet
- Ziel-Leser (was sie bereits wissen)
- Ton (freundlich, neutral, meinungsstark)
- Ziel-Länge und Format (How-to, Glossar, News)
- Erforderliche SEO-Eingaben (Primäres Keyword, Ort, Produktnamen)
Speichere das Brief im CMS oder in der Datenbank, damit jeder Entwurf zu einer Anfrage zurückverfolgt werden kann.
Generieren, validieren, prüfen, veröffentlichen
Sobald das Brief gespeichert ist, ruft dein Backend die Content-Generierungs-API auf und speichert den zurückgegebenen Entwurf als neues Content-Item mit einem klaren Status (z. B. „Entwurf erstellt“). Speichere sowohl die gesendeten Eingaben als auch die vollständige Antwort, damit du das Ergebnis später reproduzieren kannst.
Bevor ein Mensch es sieht, laufen schnelle automatisierte Prüfungen. Hier sparen Teams oft am meisten Zeit.
Halte die Checks praktisch:
- Pflichtfelder existieren (Titel, Beschreibung, Slug, Tags)
- Offensichtliche Duplikate (gleiches Thema, gleicher Slug, nahezu identische Einleitung)
- Formatierungsregeln (Überschriften vorhanden, Absätze nicht zu lang, verbotene Phrasen)
- Grundlegende SEO-Sanity (kein Keyword-Stuffing, Überschriften passen zum Inhalt)
- Bildanforderungen (ein Prompt existiert oder ein Asset ist ausgewählt)
Dann route den Entwurf automatisch an die richtige Prüfer-Queue. Produkt-Posts können an den Product-Owner gehen; sensible Themen an eine dedizierte Queue.
Wenn ein Prüfer freigibt, sperre die Version. Friere den exakten Text und die Metadaten ein, die ausgeliefert werden sollen, während neue Versionen für künftige Änderungen erlaubt bleiben.
Schließlich: veröffentlichen oder planen. Protokolliere Ergebnisse wie Veröffentlichungszeit, CMS-Entry-ID und spätere Performance-Signale. Wenn du CTA-Varianten generierst, speichere, welche Variante ausgeliefert wurde, damit du die Ergebnisse vergleichen kannst.
Review und Freigabe einrichten, ohne zu verlangsamen
Ein guter Review-Fluss bedeutet schnelle Entscheidungen mit klaren Begründungen und einer verlässlichen Audit-Spur.
Editoren arbeiten schneller, wenn sie sehen, was sich geändert hat, kontextuell kommentieren können und fokussierte Änderungswünsche senden, ohne das ganze Brief umzuschreiben. Wenn du mehrere Runden unterstützt, sorge dafür, dass das System den Kontext mitträgt.
Entscheide, was automatisch freigegeben werden kann
Nicht jedes Stück braucht das gleiche Prüflevel. Schone menschliche Aufmerksamkeit für Dinge, die deiner Marke schaden können.
Eine praktische Regel:
- Auto-Freigabe für risikoarme Korrekturen wie Rechtschreibung, Formatierung und kleine Metadaten-Anpassungen.
- Editor-Review erforderlich für neue Artikel, neue Behauptungen oder größere Umschreibungen.
- Fachliche Prüfung bei medizinischen, rechtlichen, finanziellen oder sicherheitsrelevanten Inhalten.
- Markenprüfung bei sensibler Tonalität oder Namensgebung.
- Faktenprüfung bei Inhalten mit Zahlen, Vergleichen oder Zitaten.
Setze diese Regeln als Gates im CMS-Statusmodell durch. Ein generierter Entwurf kann automatisch von „Entwurf“ zu „Braucht Prüfung“ wechseln, aber nur eine Editor-Rolle darf auf „Genehmigt“ schalten.
Mehrere Runden handhaben, ohne Chaos
Behandle jede Revision als neue Version und halte Freigaben an eine bestimmte Version gebunden.
Ein skalierbares Muster:
- Sperre die freigegebene Version, während auf einer neuen Revision editiert wird.
- Hänge Kommentare und Änderungswünsche an eine spezifische Version.
- Setze maximal zwei Review-Runden, bevor auf ein kurzes Live-Gespräch eskaliert wird.
- Verfolge, wer wann freigegeben hat.
Beispiel: Ein Autor bittet um eine Neuformulierung nach einem Produktupdate. Der Generator erstellt einen neuen Entwurf. Der Editor sieht nur die betroffenen Abschnitte im Diff, hinterlässt zwei Inline-Kommentare und markiert „Änderungen angefordert“. Die nächste Version kommt mit den behobenen Punkten zurück und wird schnell freigegeben.
Publishing-Details: Metadaten, Bilder und Planung
Briefings schnell in Entwürfe verwandeln
Erzeuge Entwürfe, Metadaten und statusbereite Inhaltsobjekte aus einem wiederverwendbaren Briefing.
Veröffentlichen ist der Moment, in dem gute Entwürfe zu Seiten werden, die Leute anklicken und lesen. Die wichtigsten Details sind Metadaten, Bilder und Timing.
Metadaten: entscheiden, was generiert vs. editiert wird
Wähle für jedes Feld eine einzige Source of Truth. Eine übliche Aufteilung: Das Brief setzt die Absicht, der Generator schlägt Optionen vor und ein Editor trifft die finale Entscheidung für alles, was öffentlich sichtbar ist.
Behandle diese Felder explizit: Titel, Slug, Meta-Beschreibung, canonical (falls nötig), Kategorie/Tags, Autor/Datum. Lass den Generator ein paar Optionen vorschlagen, speichere aber die vom Editor gewählte Version als die veröffentlichungsfähige. Halte interne Notizen (Ziel-Keyword, Angle, Zielgruppe) getrennt von öffentlichen Metadaten.
Bilder: wie Content, nicht Anhänge
Bilder brauchen einen eigenen Mini-Workflow. Speichere ein Bild-Brief zusammen mit dem Artikel-Brief, dann generiere, prüfe und veröffentliche mit klaren Status.
Ein einfacher Ablauf:
- Schreibe einen Image-Prompt basierend auf dem Artikel-Angle (plus Markenregeln).
- Generiere ein paar Optionen und wähle eine aus.
- Skaliere auf benötigte Größen (Hero, Social, Thumbnail) und komprimiere.
- Schreibe Alt-Text, der das Bild beschreibt, nicht das Keyword stopft.
- Speichere Credits oder Lizenzhinweise (falls genutzt) und finale File-IDs im CMS.
Publish-Format: Markdown, HTML oder CMS-Blöcke
Wähle ein Format, das zu deinem Rendering-Setup passt. Markdown ist leicht zu speichern und zu prüfen. HTML ist direkt, aber schwerer sicher zu editieren. CMS-Blöcke sind gut für komplexe Layouts, erfordern aber mehr Arbeit für Generatoren.
Ein gängiger Ansatz ist, Markdown zu speichern, beim Veröffentlichen zu HTML konvertieren und strukturierte Metadaten (FAQ, Key-Takeaways, Produktnennungen) in separaten Feldern zu halten.
Planung: Zeitzonen, Embargos und Backfills
Planung bricht, wenn Zeitzonen vage sind. Speichere publish_at in UTC, zeige die Zeitzone des Editors separat an und protokolliere Zeitplanänderungen.
Embargos lassen sich einfacher handhaben, wenn du sie modellierst: Inhalte können „genehmigt“ sein, aber bis zum Ende des Embargos blockiert bleiben. Bei Backfills (ältere Beiträge, die du migrierst) behalte ein original_published_at-Feld, damit das richtige Datum angezeigt wird, ohne Sortierung oder Analytics zu zerstören.
Beispiel: Ein Editor genehmigt einen Beitrag am Freitag, plant ihn für Dienstag 09:00 America/New_York und setzt ein Embargo bis zur Produktankündigung. Die Pipeline hält alles bereit und ändert den finalen Status auf „Veröffentlicht“, wenn beide Bedingungen erfüllt sind.
Häufige Fehler und Fallen, die du vermeiden solltest
Eine API-Pipeline kann sich automatisch anfühlen — bis zu dem Tag, an dem sie stillschweigend etwas Kaputtes veröffentlicht. Die meisten Fehler haben nichts mit dem Modell oder dem CMS zu tun. Sie entstehen durch fehlende Schutzmechanismen.
Eine gängige Falle ist partielles Veröffentlichen. Der CMS-Post wird erstellt und indexiert, aber der Hero-Image-Job scheitert oder der Metadaten-Schritt läuft ins Timeout. Leser:innen landen auf einer halbfertigen Seite und dein Team räumt das manuell auf. Behandle Veröffentlichen wie einen einzigen Release: valideRequired-Felder prüfen, Assets bestätigen und erst dann veröffentlichen.
Eine andere Falle ist unklare Ownership. Wenn Freigabe geteilt wird, aber niemand verantwortlich ist, stapeln sich Entwürfe. Nenne eine:n Owner pro Content-Item und gib dieser Person eine klare „freigeben“- oder „Änderungen anfordern“-Aufgabe.
Regeneration ist leicht zu missbrauchen. Wenn du nach einer Editor-Änderung regenerierst, kannst du echte Edits überschreiben. Sperre oder snapshotte die freigegebene Version und erlaube Regeneration nur in einem spezifischen Status wie „Entwurf“ oder „Braucht Umschreiben“.
Typische Probleme:
- Veröffentlichen ohne „alle Checks bestanden“-Gates (Bilder, canonical URL, Schema, Kategorien).
- Keine einzelne:n Approver:in, oder Freigaberegeln nicht dokumentiert.
- Regenerieren zur falschen Zeit und Überschreiben von Editor-Updates.
- Neue Posts erstellen, ohne auf ähnliche Themen zu prüfen (Keyword-Kannibalisierung).
- QA bei Titeln, Slugs und Meta-Beschreibungen überspringen.
Schutzmaßnahmen, die echten Schmerz verhindern: halte ein leichtgewichtiges Themen-Register, um Duplikate früh zu erkennen; füge einen finalen QA-Schritt hinzu, der Titel-Länge und Pflicht-Metadaten prüft; und mache die Publish-Operation so, dass sie sicher erneut ausgeführt werden kann, damit ein temporärer Fehler keine Doppelposts erzeugt.
Kurze Checkliste bevor du auf Veröffentlichen drückst
CTAs in jedem Beitrag testen
Erzeuge CTA-Varianten für jeden Artikel und tracke, welche am besten performen.
Kleine Fehler werden zu großen Ärgernissen: falscher Slug, fehlende Metadaten oder ein Entwurf, der nie wirklich freigegeben wurde. Eine kurze Checkliste hält die Pipeline zuverlässig, auch bei hohem Veröffentlichungsvolumen.
Content-Readiness:
- Bestätige, dass ein Brief existiert (Zielgruppe, Ziel und die Aktion, die Leser:innen ausführen sollen).
- Bestätige, dass du die neueste freigegebene Version veröffentlichst (Version-ID und Status stimmen überein).
- Prüfe Titel und Slug auf Lesbarkeit und Einzigartigkeit.
- Prüfe den Such-Snippet: die Meta-Beschreibung sollte konkret sein und das Versprechen des Beitrags widerspiegeln.
Technische Publish-Checks:
- Bilder validieren: richtige Größen, sinnvolle Dateinamen und beschreibender Alt-Text.
- Den Publish-Job ausführen und die Erfolgsmeldung speichern (CMS-Entry-ID, finaler Slug).
- Planungsdetails prüfen, einschließlich Zeitzone.
- Mess-Tags anhängen bestätigen, bevor der Beitrag live geht.
Beispiel: Wenn ein Editor Version 7 freigibt, die Pipeline aber Version 6 veröffentlicht, sieht alles bis jemand den falschen Absatz im Produktivsystem bemerkt gut aus. Vermeide das, indem du die freigegebene Version-ID und den Status im selben Schritt prüfst, der das Veröffentlichen auslöst.
Beispiel-Workflow und praktische nächste Schritte
Stell dir ein kleines Marketingteam vor, das konsistent veröffentlichen will, ohne die halbe Woche mit dem Kopieren zwischen Tools zu verbringen. Sie halten ein Backlog mit Themen im CMS und zielen auf fünf Entwürfe pro Woche. Das Ziel ist eine Pipeline, die ein Briefing in einen Entwurf verwandelt, ihn zur Prüfung routet und mit den richtigen Metadaten plant.
Ein Artikel Ende-zu-Ende:
- Brief erstellt: Ein Marketer trägt Thema, Zielgruppe, Keywords und Notizen ins CMS ein.
- Entwurf generiert: Ein Worker holt das Brief, ruft die Generierungs-API auf und speichert den Entwurf als „Braucht Prüfung“.
- Editor-Review: Der Editor editiert im CMS und genehmigt oder fordert Änderungen an.
- SEO und Assets: Titel, Meta-Beschreibung und Alt-Text werden geprüft; ein Bild wird angehängt.
- Geplante Veröffentlichung: Der Beitrag wird für einen bestimmten Zeitpunkt geplant und auf „Geplant“ gesetzt.
Wenn der Editor eine Neuformulierung verlangt, überschreibe den Entwurf nicht blind. Erstelle eine neue Revision mit einem klaren Grund (z. B. „Ton zu werblich“ oder „Beispiel fehlt“) und führe die Generierung mit den Notizen des Editors als Einschränkungen erneut aus. Bewahre beide Versionen, damit du sehen kannst, was sich geändert hat und denselben Fehler nicht wiederholst.
Nach der Veröffentlichung verwandelt Logging ein „wir denken, es hat funktioniert“ in klare nächste Schritte. Tracke einige Signale für jeden Post: Zeit von Brief bis Publish (und wo es festhing), Rewrite-Zyklen, organische Impressions und Klicks, CTA-Views und Konversionen (falls CTAs verwendet werden), Indexierungsstatus und Publish-Fehler.
Nächste Schritte: Fang klein an. Automatisiere zuerst die Entwurfserstellung und Statuswechsel, dann füge Bilder, Planung und Performance-Tracking hinzu. Sobald die Grundlagen stabil sind, erweitere auf Übersetzungen und schnellere Indexierung.
Wenn du die Integrationsoberfläche klein halten willst, kann GENERATED (generated.app) als API-Schicht für das Generieren und Polieren von Texten, das Erzeugen von Blogbildern und das Erstellen von CTA-Varianten mit Performance-Tracking dienen, während dein CMS die Source of Truth für Freigaben und Veröffentlichungen bleibt. Es unterstützt außerdem mehrsprachige Workflows und schnellere Indexierungsoptionen wie IndexNow, was natürlich passt, sobald deine Pipeline Status und Veröffentlichungsereignisse bereits verfolgt.